


Every post on June is related to algorithms, anchored on The Algorithm Codex. I’m also running an experiment this month: stretching the pace to one-post-a-day with per-day theme. Monday is for Mind-blowing. Let’s see how that goes.

When someone tells you they have the “fastest algorithm ever devised”, you probably think they bumped into trick to make clever use of the cache, or something equally tasteless, perhaps Youtube-worthy for 2 hours. I know I’d do if you came to me with this title.
But this is not that post. This is about the actual fastest algorithm we have ever devised, and probably the fastest anyone will ever do. And not in a trivial sense. There is one problem in computer science (practical, appearing everywhere you look, explainable in two sentences) where we have an algorithm, a correctness proof, a complexity bound, and a matching lower bound that closes the problem.
Done. Problem solved. No more papers.
That kind of closure is the rarest thing in any field of human knowledge.
Four conditions, one winner
But what does “fastest algorithm” mean? There are many ways you can interpret this phrase, and some of them are trivially true.
Reading an entry from an array takes constant time. Nothing beats that. But it’s one operation on a flat structure, no progression, nowhere lower to go. Getting the title should require something harder.
The interesting frontier is a non-trivial problem with a naive solution everyone reaches for, and another, mindblowingly faster solution that is provably optimal. The problem we analyze today has four traits we want:
First, general: appears in real systems across many domains, not a toy. Second, explainable in two sentences: if you need a paragraph to state it, the optimality result arrives too late to matter. Third, a real progression from naive to optimal: intermediate ideas that each earned their place, not a single flash of inspiration. Fourth, provably closed: algorithm and lower bound meet exactly. Not “hard to improve.” Closed.
Our problem is Union-Find, which clears all four. Nothing else with a non-trivial structure clears them as cleanly. Let me explain it to you in two sentences.
You’ve used this all day
Union-Find goes like this. You have n things, organized into groups. You need to merge two groups and ask whether two things are in the same group.
That’s it. No deletion. No ordering. No traversal. Two operations on a shifting partition: union and find.
You’ve used it today, probably without noticing. Your phone’s photo app groups every selfie of the same person into a face album by computing connected components, and connected components is what Union-Find does for a living. The bucket tool in any image editor (Paint, Photoshop, Procreate, whatever) floods a region with color by labeling connected pixels? Yes, Union-Find.
Every time your TypeScript or Rust compiler decides two variables must share a type, Hindley-Milner type inference unifies them through Union-Find. Spanning Tree Protocol, the thing that lets the switches in your office or home network agree on which links to use so packets don’t cycle forever, runs Kruskal’s algorithm; Kruskal needs Union-Find to detect cycles.
The same idea shows up across classical computer science under different names. The canonical image segmentation algorithm (Felzenszwalb and Huttenlocher, 2004) is the bucket tool’s research-grade cousin. Procedurally generated mazes in games are built by running Kruskal on a grid. Percolation theory in physics, the study of how fluids flow through porous materials, is the same partition-growing-by-merging problem in continuous form. Whenever a system has equivalence classes that grow online, Union-Find is almost always the engine underneath.
Union-Find is actually pretty simple
The naive solution is straightforward: give every element a label. To merge two groups, sweep through the array and relabel everything in one group with the other’s identifier. Works perfectly. Linear work per merge. Nothing cheaper to write, and nothing more expensive to run at scale.
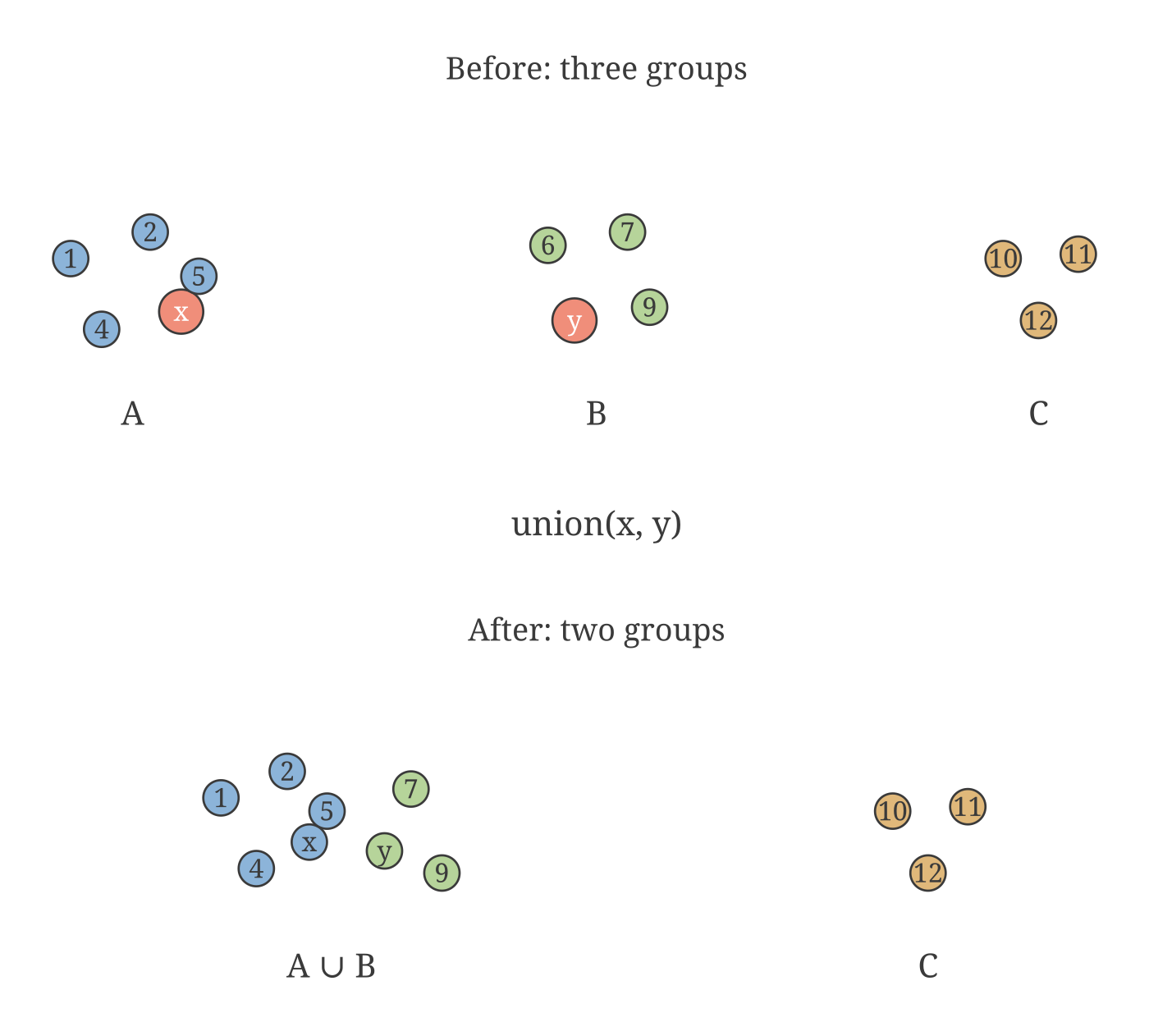
union(x, y): two. Made with Tesserax.The first idea that earns its keep is a structural change. Stop labeling every element. Give each element a parent pointer: a single reference to another element. The root of each tree is the element that points to itself, and the root names the group.
To check if two elements share a group: walk each one up its parent pointers to a root. Same root, same group.
To merge two groups: find both roots and point one at the other. One pointer write, regardless of how many elements are involved.
The trade has moved. Merge is cheap. But your find now costs as much as the tree is tall.
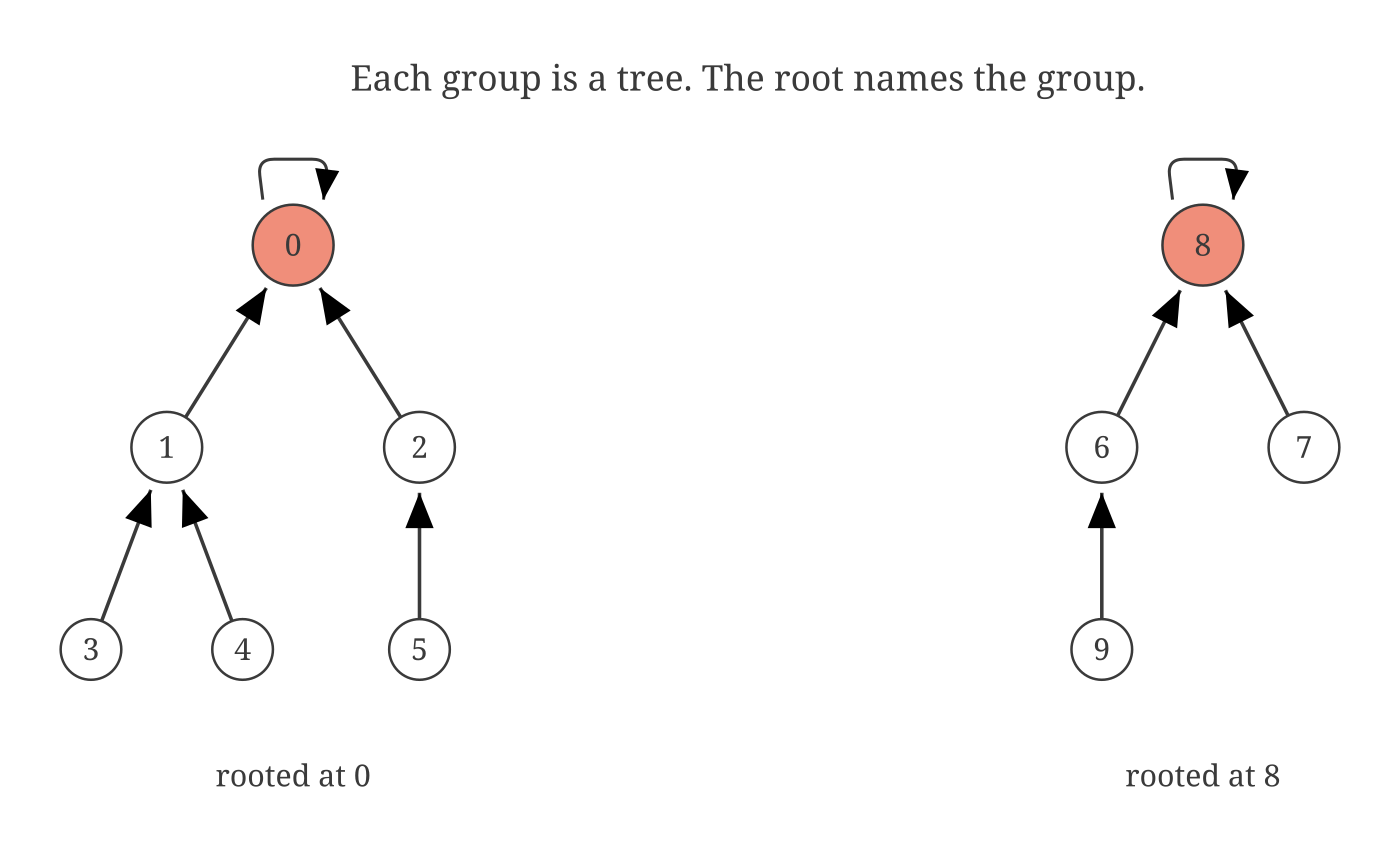
Here is the failure mode. An adversarial union sequence can build a long thin chain: element one points to element two, which points to element three, all the way down. Every find walks the whole chain. Linear again.
The rest of the story is about keeping the trees short, like, really, really short.
Making Union-Find fast, really fast
The first fix is the obvious one once you’ve seen the failure. Track each tree’s height: its rank. When merging, always hang the shorter tree under the root of the taller. The merged tree is no taller than the taller of its inputs.
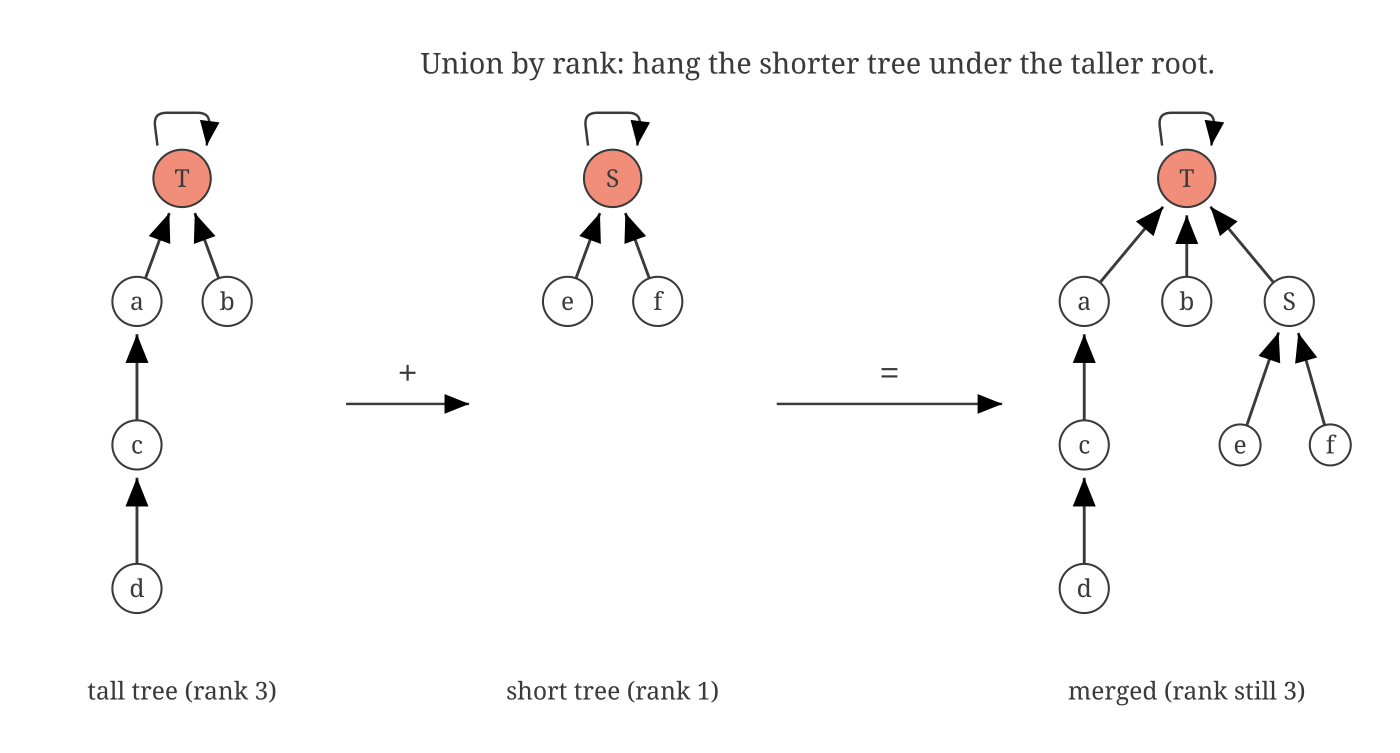
The counting argument is clean. A tree of rank r must contain at least 2r elements. You can prove it by induction on the merge rule. So the rank, which bounds the height, can never exceed log₂(n). Both operations now run in O(log n). A million elements: naive worst case is a million steps; rank-bounded is twenty.
One integer per node buys us exponential improvement in speed. Read that again.
Most algorithms textbooks would stop here. The second fix is what changes this from a really fast algorithm to the fastest algorithm ever, period.
Notice something about the walk-to-root operation. When it finishes, it has discovered the root. Every node it visited could be rewired, right now, on the way back, to point straight at the root.
The structure flattens itself, in place, every time you ask it a question. The next walk on that path takes one step. Work you already did is work you never have to do again.
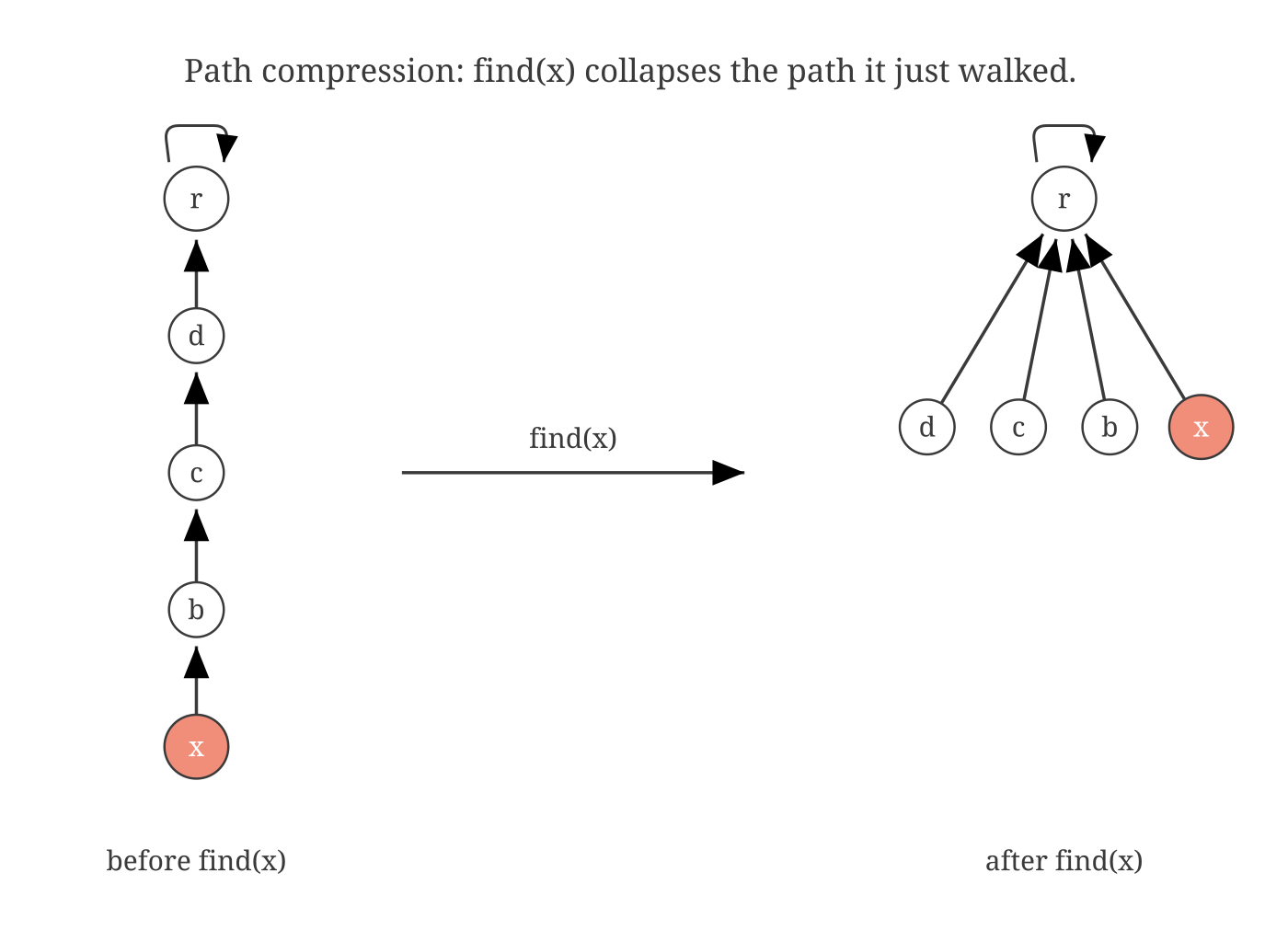
find(x) collapses the chain into a star. Every walked node now points straight at the root.On its own, this trick is good. Combined with the rank rule, the cost drops below logarithmic, into a regime that barely has a name.
¿How fast is this? Strap on, baby.
Union-Find is the fastest algorithm ever devised
Robert Tarjan, in 1975, proved the two ideas together give an amortized cost per operation of the inverse Ackermann function, written α(n).
To understand why that means fast, you need a picture of what you’re inverting. The Ackermann function grows like hell. Faster than exponentials, faster than towers of exponentials, faster than any function built by ordinary recursion. A(4, 4), only four steps in, already exceeds the number of atoms in the observable universe. It’s a freaking monster, one of the fastest growing functions ever invented.
The inverse grows correspondingly sloooowww. For any n less than 2 to the power of 65536 (a number whose decimal representation runs twenty thousand digits), α(n) ≤ 4. Read that again. For any input you could construct on any computer that will ever be built, the average cost per operation is at most four pointer hops.
Effectively constant. Call it constant, for practical purposes. But it is not constant. There is a real function in there. That fact is not a technicality. This is not a gap waiting for a smarter trick. It is a permanent lower bound, proved by Fredman and Saks in 1989.
Michael Fredman and Michael Saks worked in the cell-probe model, which counts how many stored bits any data structure must read to answer a query. They proved that Ω(α(n)) is the true lower bound for the union-find problem. No structure of any design can answer union and find queries doing less amortized work than α(n).
Tarjan’s upper bound says path-compression-plus-union-by-rank does at most α(n) amortized. Fredman and Saks’s lower bound says no structure can ever do less. The two bounds meet exactly.
Done. Problem solved. No more papers.
Problem solved is a rare luxury
Newton’s laws work until you approach the speed of light. Quantum mechanics works until you zoom out to cosmological scales. Turbulence in fluids is still open. It has been for a century. The three-body problem is still open. Physics doesn’t finish; it hands off. Every theory we have is a model that fits data within its domain of validity, and I think we forget how strange that is.
The Schrödinger equation describes how electrons move in any atom. For helium (two electrons) it has no closed-form solution. The electron interactions couple (each one affecting all the others) in ways that resist exact treatment. Chemistry approximates, and the gap is permanent, not a waiting-for-faster-computers problem.
Mathematics does close problems, and famously. Wiles closed Fermat’s Last Theorem in 1995, after the conjecture had sat open for 358 years. The four-color theorem closed in 1976 (with a computer’s help, which still rankles some). Poincaré closed in 2003. But the closures cluster on problems mathematicians chose: beautiful, deep, and often distant from anything that runs in your hand.
Computer science almost never gets all three at once. A problem that is practical, used in real systems every day; crisply specified, fitting in two sentences; and provably closed, algorithm and lower bound matched exactly. Union-Find is in this corner. Comparison-based sorting being Θ(n log n) is in it. Linear search on unsorted data being Θ(n) is in it. The list is short.
Algorithm and lower bound, meeting exactly.
Done. Problem Solved. No more papers.
The fastest non-trivial algorithm ever devised takes twenty lines to write, runs in essentially constant time per operation, and is one of the very few things we have ever — in any field — entirely finished.
If that isn’t freaking mind blowing, I don’t what is. Until next time, stay curious.
Union-Find is chapter 14 of The Algorithm Codex, a book that spells out the algorithms every programmer eventually meets in real, functioning Python — no pseudocode bullshit, no complicated math.
Every chapter ends with the same three questions: is it correct? how efficient? is it optimal? Most chapters land two out of three. A small few land all three. Union-Find is the cleanest example in the book of all three boxes ticked.
with regards to modern-day LLM's, this means that the pretraining data is your dataset. the post-train response tuning and reinforcement stack represents the organization of the dataset. optimal search is exploiting how the post-trained tuning interacts with the dataset.