

Chat with your PDF
Build a simple streamlit app using LLMs and vector databases to answer arbitrary questions from a PDF document

Welcome to the first coding lesson in Mostly Harmless Ideas. This is an experimental section where I want to share very concrete, project-based coding lessons for all types of learners and all experience levels. I’m still figuring out the best format for these, so please let me know what works and what doesn’t for you.
Today’s lesson is about building a bare-bones app to answer arbitrary questions from a PDF file. We will use mistral.ai as the provider of language models, which has some incredibly powerful open-source LLMs1.
Here’s a quick look at the final application, answering questions on the latest draft of my upcoming book The Science of Computation.
The full source code (minus Mistral API keys) is located here.
Note: This post will be truncated in your email. View it online here.
Prerequisites
This lesson is somewhat advanced, so I expect you to be comfortable with basic Python and building simple apps in streamlit, although most of the streamlit code will be self-explanatory.
You must also know how to set up a basic Python project using a virtual environment and install dependencies from requirement files. If you need help with any of these topics, check out The Python Coding Stack • by Stephen Gruppetta and Mostly Python for plenty of beginner-friendly articles.
You don’t need prior knowledge of using LLMs or vector databases or building chat-based apps.
Making a Chat with your PDF app
Since this lesson is for advanced readers, I won’t explain the code step by step. Instead, I will give you a very high-level description of the architecture of the app (which you will see is extremely simple), and then I will zoom into those implementation details that are crucial, leaving aside the boilerplate code.
My purpose is that you understand how each functionality is implemented and how they fit together, so when you read the actual code, everything clicks into place. For this reason, I won’t go line by line either but rather look at fundamental blocks in the order that makes understanding the app workflow easier.
At a high level, this is a typical streamlit application with a simple layout. It has a sidebar where the user can upload a PDF file, and the main content is a container for chat UI elements.
The workflow is as follows:
The user uploads a PDF file.
Using the pypdf module, we extract the plain text and split it into overlapping chunks.
Each chunk is transformed into a vector, using Mistral’s embeddings via the mistralai module.
The embeddings are stored in a flat in-memory vector index using faiss.
Then, a query/response cycle is run, using one of Mistral’s LLMs, with a custom prompt that injects the most relevant chunk of the document for a given user query.
But the devil is in the details, so let’s dive in.
PDF processing
Let’s start by analyzing the PDF processing step. Although this is almost the last piece of code written, it is the starting point that triggers the whole workflow.
As is typical in Streamlit, we use a widget to let the user upload a PDF file and store the resulting object in a global variable.

However, since we want to do batch processing with it, and Streamlit runs this script every time something changes, we will use a callback that is only invoked when a new file is uploaded via the on_change parameter. (Notice we name the widget with a custom key, this will be important soon.)
The build_index function gets called whenever the PDF widget changes, that is, when the user selects a new file.

The first part of this function is straightforward. We take care of the case when there is no PDF uploaded (the use of session_state.messages will be clear later on), and then proceed to extract the text from the PDF.
Notice we obtain the PDF file from the session_state.pdf_file key, which is exactly the key we used when naming our PDF upload widget. This is one of the ways you can connect different widgets in Streamlit without using global variables.
The last two lines of this first part of the function store the extracted text in the session state dictionary for later use and output a helpful message indicating the size of the uploaded document. This is mostly so the user knows something is happening, as the whole indexing can be slow.
Next comes the actual indexing part.

First, we split the text into chunks of 2048 characters, with an overlap of 1024. This is the crudest way to split a text document into meaningful parts, but it works as a proof of concept. The overlap ensures that if we (almost certainly) split an important sentence in half in one chunk, we will get a second chance to store it in full in the next chunk.
After the chunks are created, we will compute an embedding for each. The embed function (which we will see in a minute) calls the Mistral API and returns a vector (in the form of a list of float numbers). We stack them all together using numpy and create a huge matrix that has one row per chunk.
Finally, we use faiss’ IndexFlatL2 class to store all the embeddings in an efficient data structure we can query later. We then store both the index object and the chunk list in the session state because we will need to recover the actual chunks using this list.
Answering questions
The question-answering part is the core of the application. We implement this functionality in a function reply that answers a single query. Then, we’ll see how this all fits together with the app workflow.
Here it is:

The first two lines compute the query embedding, which we use to find the closest chunk in the index in the next two lines.
Then, we use the Mistral API to query the LLM with a single message (the user query), but —here is where the magic happens— that query is wrapped in a custom prompt that injects the most relevant chunk of text (according to the embeddings at least) along with some instructions for the LLM.
Here is that prompt:
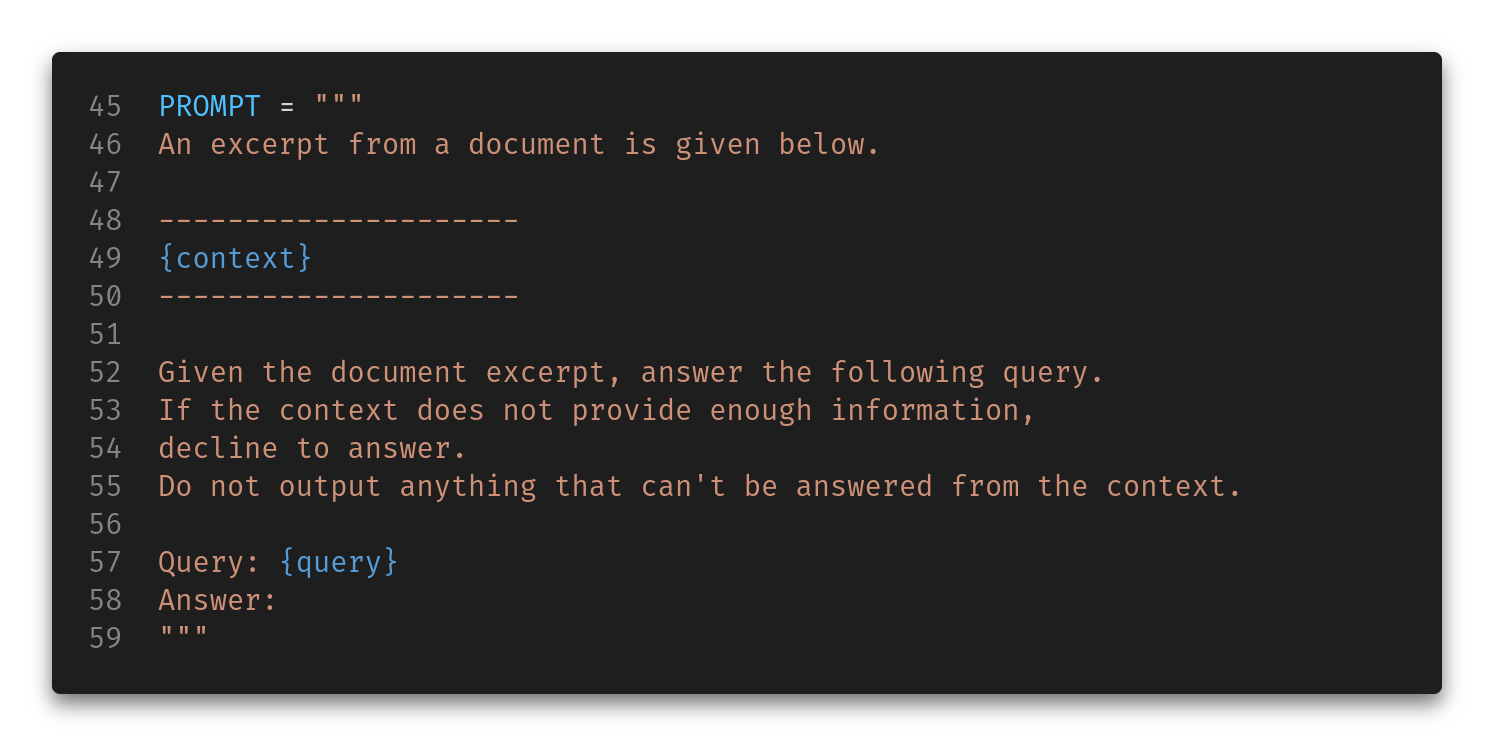
Because LLMs are pretty insane, this actually works most of the time. The LLM will see a block of 2048 characters closely related to the query and will almost certainly manage to extract the relevant part from that blob of text to answer the query.
Two details are still missing from this part. One is the instantiation of the Mistral API client, which is pretty straightforward, provided you have the right API key in the Streamlit secrets file:

The @st.cache_resource decorator avoids creating a new API client on every run.
The second implementation detail missing is the embed method, which basically just calls the Mistral API. We add the @st.cache_data decorator to save us from recomputing embeddings for the same blocks of text over and over.

Chat management
Now that we know how to reply to one user query, let’s see how the actual conversation workflow works. We need to solve two things: persist the conversation history despite Streamlit’s stateless execution model and simulate the typing animation. The following function takes care of that:

The key pieces of this functionality are the following. We use st.write_stream instead of the typical st.write to simulate the typing animation. This method receives an iterator of printable stuff (e.g., characters). In the case of the actual LLM response, we will receive an iterable of responses. The following function (used in reply) unwraps the response content, turning the LLM stream into a simple string iterable.

For our system messages (like the welcome screen), we must wrap that string in a function that yields each character at a time.

The last part of the add_message function simply stores the message just streamed in a session state list so that, in the next execution, we can rewrite all previous messages and simulate a persistent conversation.
Putting it all together
Now that we understand all the puzzle pieces let’s see how they fit into the main application workflow. The first step is to initialize the session state variable to hold our chat history (if this is the first run) and then write that history back into the chat container every other run.

Next, we show an introductory message only if we haven’t done the PDF processing yet (remember we store the PDF text in the session state when we do). These two messages will not be stored in the chat history so they will be replaced once we upload the PDF.

Nex comes the PDF upload widget we’ve already seen. Once we have a PDF uploaded, we take the user query.

We also retrieve the IndexFlatL2 from the session state for use in the next fragment.
And finally, we send the query to the LLM to compute the reply. However, the first time, we will add a custom query that simply asks for a document summary.

Final remarks
And that’s it! In a little more than 200 lines of code, you got yourself a fully functional, although simple, app to chat with an arbitrary PDF file. All thanks to the magic of LLMs and the simplicity of the streamlit framework,
There are some obvious limitations in this implementation, though. Here are some of the most relevant, which can give you ideas to improve it.
Only the last message is sent to the LLM, so even though the whole conversation is displayed constantly, every query is independent. That is, the chatbot has no access to the previous context. This is easy to fix by passing the last few messages on the call to
client.chat_stream(...).To save resources, documents with more than 100 chunks will error. This number can be changed in the source code.
There is no caching of queries, only embeddings. The same query will consume API calls every time it’s used. This is relatively easy to fix by caching the query before submission, but you cannot simply use
st.cache_*because the response is a stream of data objects consumed asynchronously, and the same query can have a different response per user/document.Only one chunk is retrieved for each query, so the model will answer incorrectly if the question requires a longer context.
There is no attempt to sanitize the input or output, so the model can behave erratically and exhibit biased and impolite replies if prompted with such intention.
All LLMs are subject to hallucinations, so always double-check your responses.
And now we’re done! Feel free to clone and modify this project to your needs, and please let me know if you enjoyed this lesson, especially if this format is engaging and informative for you. All feedback is appreciated!
The lessons are 100% free but really hard to make. I would appreciate a like and a share if you think they're worth it :)
I’m using Mistral’s hosted LLM service because running such a beefy model locally is pretty intense, and their prices are very competitive, but the fact that it’s open-source means you can decide tomorrow to download and run the model yourself.
While the coding is above my paygrade, I absolutely appreciate the clean and hands-on nature of this. Very well done. For the code snippets, it looks like you just make screenshots? Guess you're not a fan of Substack's built-in "code block" template?
Also, the speed of your final app is impressive - there's almost no latency at all. Is that due to Mistral's innate response speed? Definitely faster than my experience with GPT-4.
Alex, have you played with ChatPDF yet?