

Let's build our own ChatGPT
Build your own chat with an LLM application in just 56 lines of code and 15 minutes.

This article is part of my upcoming book How to Train your Chatbot. You can get early access to the book and unlock all these perks:
Lifetime access to all future updates of the book.
Full access to the source code with a commercially usable license.
Online demos of all applications (soon).
A private Discord space where you can ask anything (soon).
The early access pass is 50% off for the rest of April.

In this article, we will build a simple ChatGPT clone. We will emulate the basic chat workflow, maintaining the conversation context over several interactions.
There are a ton of ChatGPT clones out there, and ours won't be anything extraordinary, but it will lay the groundwork for future LLM applications we will build in this series.
In this article, you will learn:
What is the difference between system, user, and assistant roles.
How to set up a basic conversation loop with an LLM model.
How to stream the chatbot response to simulate a typing animation.
How to simulate the bot memory by storing the conversation history.
Furthermore, in this article, we will build critical functionalities that we'll use in future applications, such as conversation management with automatic history tracking, so we never need to write that functionality again.
NOTE: This post will be cut in your email browser. Read it online instead.
Initial setup
We will use the Python library streamlit to build the front end of our application. Streamlit is a straightforward framework for creating data science apps focusing on productivity over fanciness. This means our artistic freedom is greatly restricted, and all our apps will look the same boring way, but we will need zero HTML or CSS, and development will be a breeze.
As for the LLM, I will use Mistral.ai as the provider. They’re one of the mainstream LLM makers, just behind OpenAI, Google, and Meta in scale. They are very reliable and distribute several of their models as open source, so even though we’ll be using their cloud-hosted models in this article, you won’t be tied to their platform. You can take the same models and host it on your own infrastructure whenever you choose to.
The setup of this project will thus be simple. Our only major dependencies are streamlit and mistralai. We’ll start by creating a virtual environment and installing these dependencies.

After the initial creation, it will be convenient to dump our environment setup to reconstruct the same environment later.

Basic chat app
A streamlit application can be as simple as a Python file. Here’s the basic layout of a chat app that just echoes what you type.

Assuming this code is located at code/chatbot/app.py, we can run it with:

A browser will automatically open and show something like the following:

This is just a barebones app with no chat functionality at all. It will simply write anything you type in the input box back into the chat screen. But it will help us understand the basic application lifecycle in Streamlit.
The code above is the blueprint for a typical Streamlit app. You start by importing streamlit and setting up the page title and icon and then proceed to include any number of Streamlit statements. The code is executed top-to-bottom synchronously by the Streamlit server, and all commands are sent via WebSockets to a web app. There are no callbacks or hidden states.
If this sounds alien, don’t worry. It just means a Streamlit app works like a regular Python script: you can have global variables, methods, and classes and use them as you would in a terminal script, and it will (mostly) magically work.
The first interaction with an LLM
Ok, it’s time for the real thing. Let’s send our first message to a language model! This is easy using the mistralai package. We just need to instantiate a MistralClient and call its chat method.
First, we will need an API key from Mistral.ai. This token is a password that grants your code access to the model. Beware not to share it with anyone, or they can use the API on your behalf (and you’ll pay for it). Paste the API token into .streamlit/secrets.toml like this:

Now, we can use Streamlit’s native secret management to inject this token into our application without having to copy/paste it every single time.

Once our client is set up, we must change our chat workflow to call the LLM API and output that response.

Hit R on Streamlit to hot-reload the code and type something fancy in the input box. Maybe something like “What is the meaning of life?”. In the blink of an eye (or maybe a couple of lazy eyes), your message will be sent to the LLM API, and the response will be streamed back to your application. Voilá, we have a ChatGPT clone!

Persisting the chat state
Not so fast! You will quickly notice there is something really unsatisfying with our current implementation. Every time you send a new message, the whole chat history is cleared!
This is due to Streamlit’s simple lifecycle. Since the script is executed top-to-bottom for every interaction, every button or key pressed essentially works as if the app was just started. There is no magic here; we haven’t done anything to store the conversation, so there is no place Streamlit could get it from. Let’s fix that first.
Streamlit provides a built-in way to deal with the state that persists across executions in the object st.session_state. This is a dict-like structure that can hold whatever we want and survives re-runs (but does not refresh the page). Technically, it’s session-associated data, meaning every different user of our web application gets their own private storage. But enough technobabble, let’s see some code; it’s easier to just show how it works.
First, we initialize the history key with an empty list, the first time the app is loaded. This goes right after the client initialization.

Next, before getting into the user/assistant chat workflow, we must reconstruct the previous chat history and render all the messages.

Then, when we retrieve the new user input, we have to remember to store it in the history.

And do the same with the LLM response.

If you run this update, you’ll notice the chat history persists throughout the conversation. However, one thing is still missing. Even though the chat interface shows all the previous messages, the LLM only receives the last message. This is evident in the next screenshot, where the chatbot fails to remember information given just before.

Remembering the context
Most LLM APIs have a straightforward way to submit a full conversation history. In the case of mistralai, the messages parameter in the client.chat method expects a list of ChatMessage instances. Each message specifies the content and a role, which can be:
system: Used to send behavior instructions to the LLM. We will see an example right away.user: Used to specify the user input.assistant: Used to specify the previous assistant input.
When you send a request to the LLM API, you can submit the previous messages (both the user’s and the LLM’s), and simulate as if the chatbot remembered the conversation. The LLM service has no actual memory, as it’s a stateless API. So, it’s your responsibility to reconstruct the conversation history in a meaningful way.
In our app, since we are already storing the conversation history in the session storage, we just need to construct the proper ChatMessage instances:

This update seems to magically add memory to our chatbot, although you need that, under the hood, there is no magic. It’s you who’s keeping track of the conversation.

Before closing, let’s take a look at the system prompt. By incorporating messages with role="system" you can guide the chatbot's behavior. In principle, this is no different from what you can do with a well-crafted user input, but some models are trained to pay special attention to system messages and prioritize them over user messages.
This means that, for example, you can override a previous instruction you gave as a user, but it will be much harder if the instruction was given as a system message. Thus, these messages often instruct the LLM to behave politely, avoid answering biased questions, etc. You can also use it to set the tone and style of the conversation.
To try this, let’s add an input box for the system messages to experiment with different prompts. By default, we’ll instruct the LLM to be nice.

And we can try it out with not-so-nice instructions. Delightful.

Streaming messages
Let’s turn the chatbot response into a nice typing animation as a final tweak. We need to do two things. First, we’ll call a different API method that returns the response as a generator instead of the whole output at once. Then, we’ll wrap that with our own generator to unpack the API response and extract the text chunks.
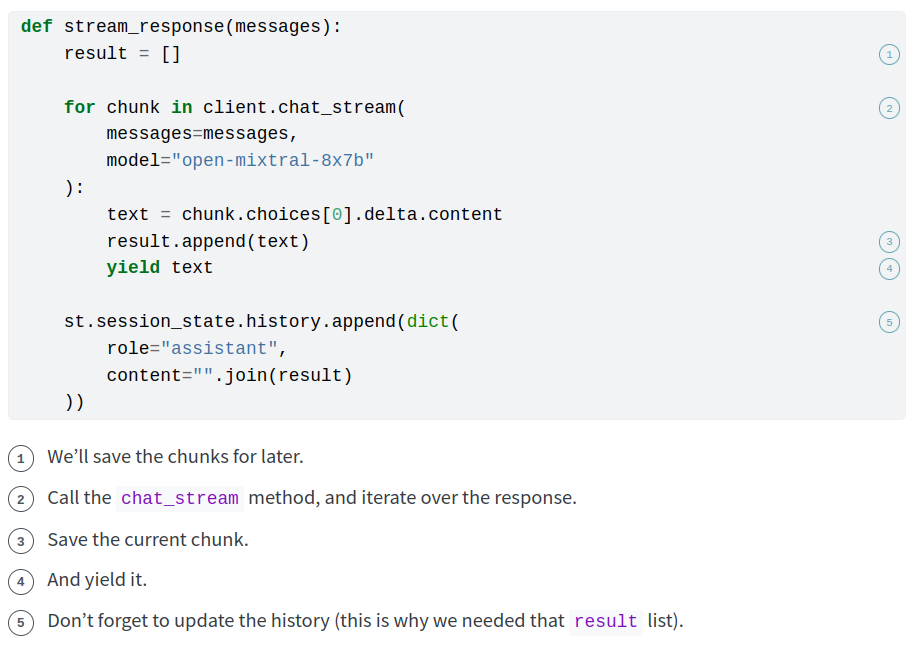
Fortunately, Streamlit has a nice functionality for rendering a text stream.

Go ahead and run this update, and you’ll see how the chatbot response is streamed almost in real-time (depending on how fast the API responds, of course). This has the upside that the user doesn’t have to wait until the generation is completed to see something, which greatly improves the experience.
Conclusions
And that’s it, our first ChatGPT clone! Nothing too fancy, but if you’ve never coded a chatbot before, this can look like magic. It certainly did for me!
The patterns we learned in this article will help us tremendously in the upcoming applications. Just to recap, this is what we’ve mastered:
How to setup a basic chat workflow, complete with history.
How to configure the chatbot with a system prompt.
How to stream the LLM response to get a fancy typing animation.
Now that we have the basic setup ready, we can start building some cool stuff.
And that’s it for today! If you’re intrigued about LLMs, please check out my in-progress book How to Train your Chatbot. Inside you’ll find 60+ pages of content, plus the full source code for this application. The early access pass is 50% off for the rest of April.
Very timely! I'm sharing this one with a friend who is trying to experiment with writing code w/LLMs. This is perfect.
Great tutorial. Really easy to follow and understand.