

How Large Languages Models Are Really Made
The full road from text data to reasoning models, explained visually with zero math or code.


You type a message to an AI assistant and it answers. The answer isn’t looked up. It isn’t scripted. The model generated it, character by character, guided by a single mathematical question: what comes next?
That question is the foundation of every language model ever built. A language model is a probability distribution over text — a function that, given a sequence of words, assigns a probability to every possible continuation. “The cat sat on the mat” scores higher than “the mat sat on the cat” not because a language model understands what cats do, but because the first sequence appears in human text and the second doesn’t. The model has compressed the co-occurrence patterns of an enormous corpus into its weights, and that compression is what produces a score.
Generative: you give the model a prefix, it samples the highest-probability next token, appends it, samples again, and repeats until a stop token arrives. The multi-paragraph response you got from ChatGPT this morning was that loop running a few hundred times. No lookup table. No if-else tree. No pre-scripted answers. Just: given all of this text, what is most likely to come next?
Here’s the thing I find quietly strange about this: it works. A procedure this simple — assign probabilities, sample the maximum — has produced the most influential technology of the last decade. What makes it work isn’t the procedure. It’s everything that goes into building a probability distribution that’s actually good. Good enough to write coherent paragraphs. Good enough to reason about code. Good enough to pass the bar exam and explain quantum mechanics in language your parents can follow.
Getting there took decades of compounding ideas. The arc is what this piece covers — from the crudest possible approximation of “probability over text” to the current frontier, where models are learning to think.
Each section of what follows is best understood as a response to the failure of the previous one. N-gram models worked until they didn’t. Neural embeddings fixed the part that broke. Pretraining scaled the fix to the size where it became genuinely impressive. Instruction tuning made the result useful for the first time. Preference learning fixed what instruction tuning couldn’t. Reasoning models added something nobody was sure was trainable at all.
Seven steps. One direction.
Every post on the blog this month is on the theme of agent reliability, anchored on the second edition of Mostly Harmless AI, where the engineering details that don’t fit a blog post live. You can also read the whole book online for free in a custom reader I built. More at the end.
This post may be truncated in your email. Read it online for the best experience.
The n-gram intuition
The simplest possible implementation of “probability over text” is a lookup table.
Take a large corpus — a hundred million words will do to start. For every three-word sequence (trigram) in that corpus, record which word follows it most often, and with what frequency. “The quick brown” → “fox,” nine times out of ten, because Project Gutenberg is full of that particular sentence. “The capital of” → “France” thirty percent of the time, “Germany” twelve, “England” eleven, and so on through the geography. For every trigram you’ve seen, you have a probability distribution over what comes next.
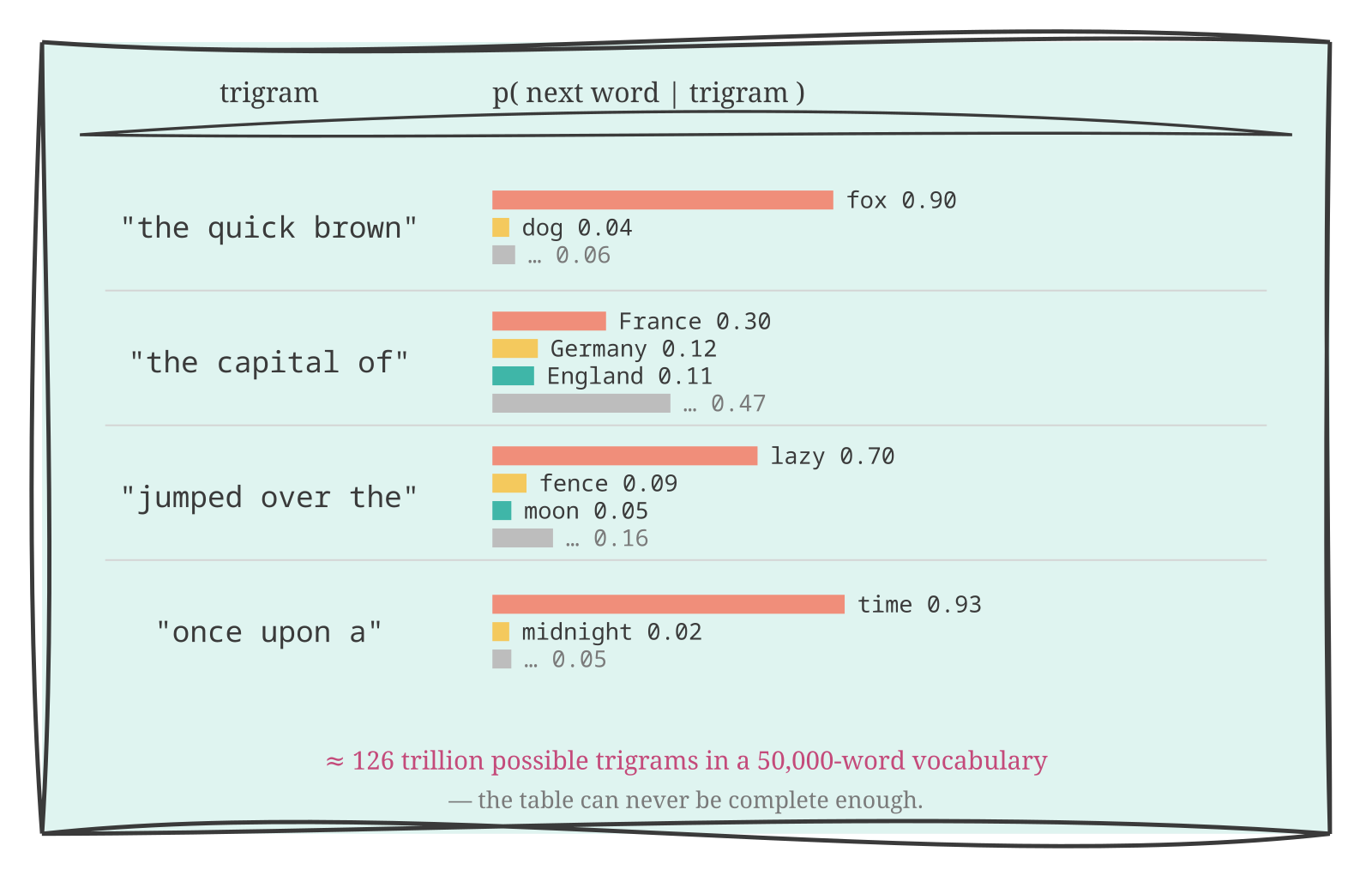
Now generate text. Give the model “The quick brown” and it continues: “fox.” Give it “jumped over the” and it continues: “lazy.” Three words in and it’s generated “The quick brown fox jumped over the lazy” — and if you’re lucky, it lands “dog” and you’ve reproduced a famous sentence entirely from corpus statistics. Locally, it’s plausible. You could read a sentence of this and not immediately know you’re looking at a machine.
The problems start fast. By the third sentence, the model has no idea it was talking about a fox. It only remembers the last three words. You ask it to continue “The fox had been running from the” and it has no idea that a fox is involved, or that running happened, or that there’s a pursuit in progress. It just has three words and a lookup table. The output is statistically English. It is not coherent.
This is the Markov assumption: the next word depends only on the last N words, not on the full history of the text. For N=3, it’s a trigram model. You can increase N — five-gram models were standard in commercial speech recognition for years — but the table explodes. Fifty thousand words in the English vocabulary gives 50,000³ possible trigram contexts, roughly 125 trillion entries. At N=10, the number of possible sequences exceeds the estimated number of atoms in the observable universe. The table can never be complete enough to cover the distribution.
There’s a real engineering solution to the “we haven’t seen this exact trigram” problem: smoothing and interpolation. Estimate the probability of an unseen N-gram from shorter sub-sequences. Hidden Markov models formalised this in a probabilistic framework that, by the 1990s, had enough polish to power industrial speech recognition and early machine translation. I don’t want to undersell it — it worked. It was genuinely useful. It just topped out.
The wall is fundamental. Real language has dependencies that can be arbitrarily long. “The man who sold the car that had been parked in front of the house where my grandmother lived was finally found.” The subject of “was finally found” is seventeen words and three nested clauses back. No N-gram model reaches it. You need something that can condition on the full context — or at least compress the full context intelligently — rather than amnesiacally forget everything more than N words ago.
You need a model that generalises from sequences it has seen to sequences it hasn’t. A lookup table can only interpolate from what it’s seen before. What you need is something that has understood the pattern deeply enough to extrapolate.
N-gram models work until they don’t — and they don’t beyond a few words.
Words as numbers
Neural networks can learn the compression n-gram models can’t achieve. But they have a hard prerequisite: they operate on numbers. Words are symbols. Before a neural network can do anything useful with text, you need to represent words as vectors. The naive approach throws away everything that matters.
The obvious first attempt is one-hot encoding. Vocabulary of 50,000 words; each word is a vector of length 50,000 with a single 1 and 49,999 zeros. “Cat” is at position 4,312; “dog” is at position 17,846; “carburetor” is somewhere else entirely. The problem: nothing in this representation suggests that “cat” and “dog” are more similar to each other than either is to “carburetor.” The distance between every pair of one-hot vectors is identical. You’ve handed the network a symbol system with no structure, and it has to reconstruct the structure from scratch — spending enormous capacity learning that cats and dogs are both animals, that both appear near “fur” and “vet,” that “cat food” and “dog food” are structurally related — before it can learn anything about how language actually works.
The key insight that resolved this came from linguistics, not machine learning, and I think it’s underrated as an idea. J.R. Firth, writing in 1957: “you shall know a word by the company it keeps.” The distributional hypothesis. Words that appear in similar contexts — near similar neighbouring words, in similar grammatical positions — tend to have similar meanings. “Cat” and “dog” both appear near “pet,” “feed,” “vet,” “owner,” “fur,” “collar.” The context is a fingerprint of the meaning. Encode that fingerprint in a vector and you have a representation where similar words land close together in space.
Word2Vec (Mikolov et al., 2013) turned this into a training procedure. Train a shallow neural network to predict a word from its surrounding context words, or vice versa. Force each word’s representation down into a dense vector of, say, 300 floating-point numbers. Train on a billion words of text. The network learns that words appearing in similar contexts should have similar representations, because that’s what makes the prediction task cheaper. Words with similar distributional patterns end up with similar vectors — not because anyone programmed that, but because it follows from the objective.
The result that made people pay attention: vector arithmetic encodes semantic relationships. Take the vector for “king,” subtract the vector for “man,” add the vector for “woman.” The nearest vector in the resulting space is “queen.” Paris minus France plus Italy is approximately Rome. Try it yourself: it works because the structural relationship between “king” and “queen” is parallel to the relationship between “man” and “woman” in how the four words co-occur with everything around them. No one wrote these analogies in. The geometry of the space mirrors the structure of meaning, because both are implicit in how words appear together in natural language.
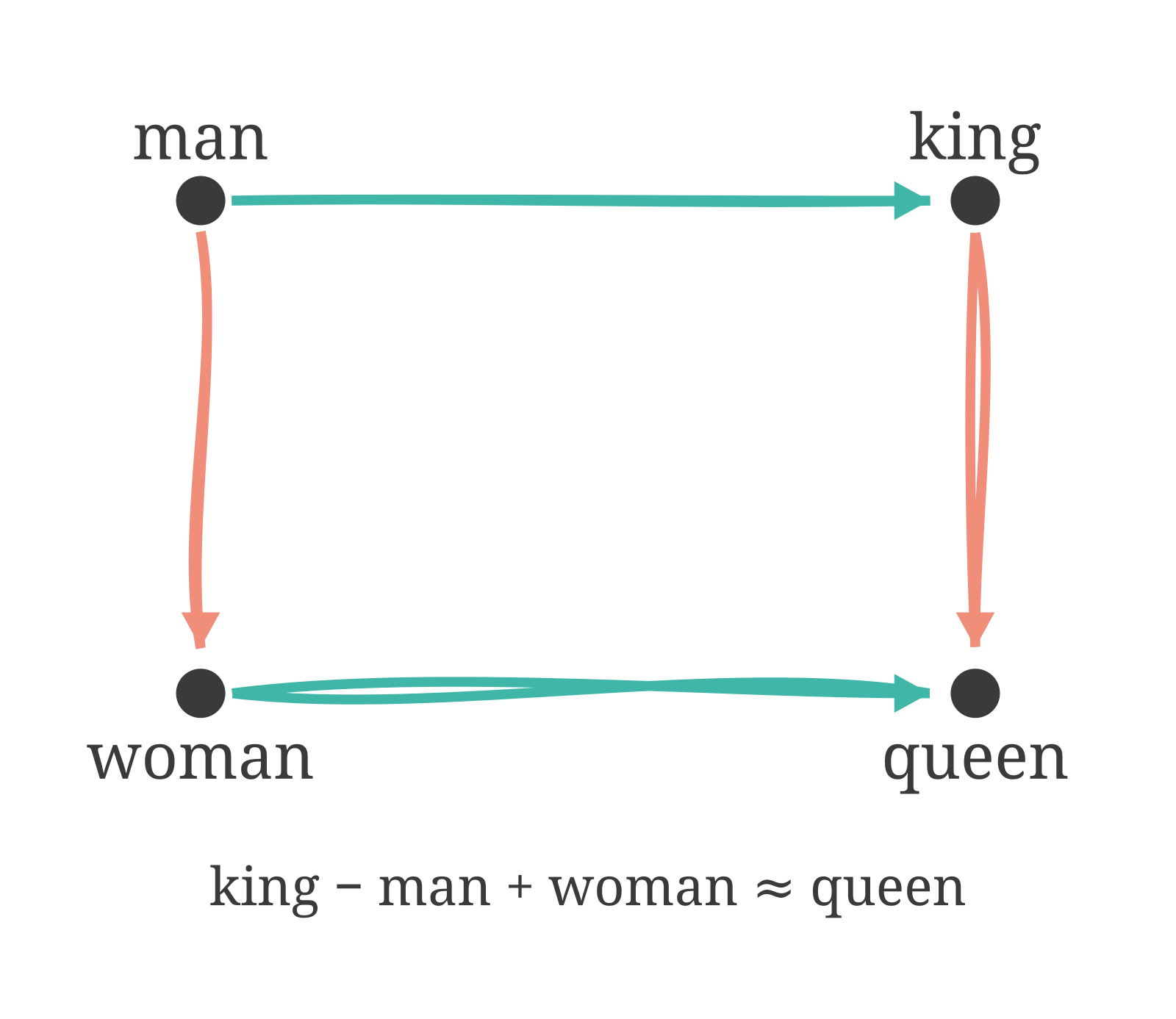
I find this genuinely strange, in the best possible way. You trained a network to do a simple word-guessing task on flat text, and the side effect was an algebra of concepts. The geometry was always latent in the co-occurrence patterns. Word2Vec just made it legible.
Modern language models don’t use Word2Vec as a separate preprocessing step — the embedding representations are learned jointly with the rest of the network during training on text. But Word2Vec’s intuition is why learned embeddings work at all. Once language is geometry, gradient descent has a surface to grip. You can compute distances, optimise them, stack arbitrarily deep networks on top, and train the whole thing end-to-end.
Embeddings are how we lie to neural networks in a useful way. We pretend words are points in space, so the math works out.
Pretraining
Now scale it.
Take a deep neural network — not the shallow two-layer thing in Word2Vec, but a transformer with dozens or hundreds of layers, billions of parameters, and an attention mechanism in every one of them. Feed it next-token prediction across the entire accessible internet: Wikipedia, GitHub, every book ever digitised, every forum thread, every research paper, every recipe, every political argument, every user manual for every piece of machinery ever manufactured. Same objective the n-gram model had: given what came before, what comes next? Except now the model has billions of parameters to compress the patterns into, the training signal is trillions of tokens, and the architecture is built to handle arbitrarily long context.
The architecture is what made everything else possible. The transformer (Vaswani et al., 2017) uses self-attention as its core operation. For each token in the input, self-attention computes relevance weights over every other token in the sequence — learned weights, computed from the data, different for each token, different in each layer. A pronoun can attend strongly to the noun it refers to, twenty positions back. A closing argument can reach back to the premise from the opening paragraph. There is no fixed window; the model considers, in principle, the full context at every step.
This is what broke the n-gram scaling wall. Not a bigger lookup table. Not smarter interpolation. A learned, flexible attention mechanism that compresses long-range dependencies into the model’s weights rather than trying to enumerate every possible context sequence. The key property, and it’s the one I keep coming back to: soft. Self-attention doesn’t pick one relevant token; it blends all of them with learned weights. The whole sequence contributes to every prediction, with a learned notion of how much each part matters.
The other critical property is self-supervised learning. There are no human-provided labels anywhere in pretraining. The text itself is the training signal. Show the model “The capital of” and ask it to predict “France.” It’s wrong; the gradient flows; the weights update. Show it three trillion tokens; let the gradient flow three trillion times. The entire digitised corpus of human knowledge is your training set, with zero labelling cost, because the next token is always right there.
Kaplan et al., 2020 measured loss as a function of model size, dataset size, and compute over seven orders of magnitude. The result: loss falls as a clean power law across all three dimensions. Double the parameters, get a predictable drop in loss. Double the training data, same. Scale is not a bet on something uncertain; it is a known return on investment, measured and re-measured across a staggering range.
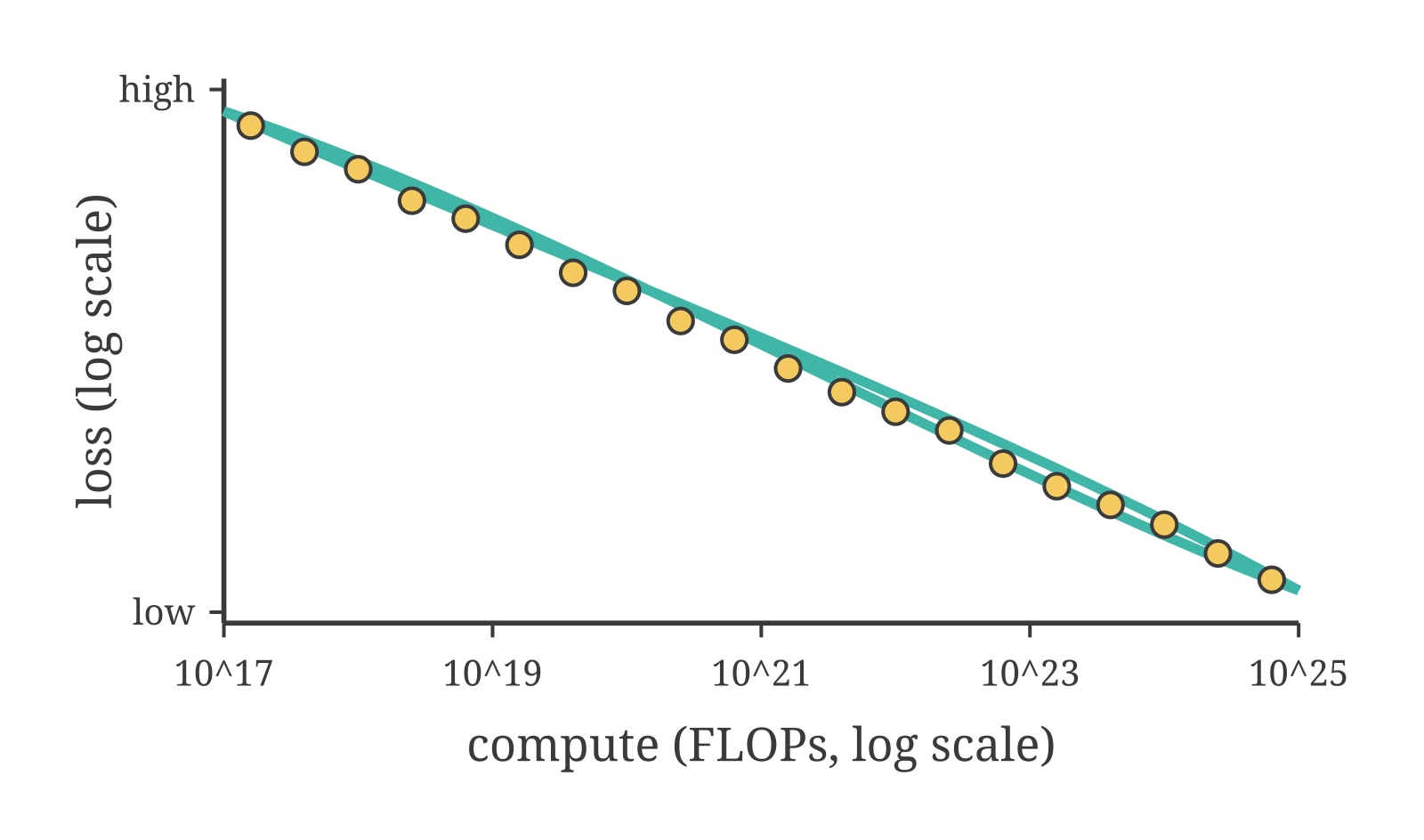
Hoffmann et al., 2022 — the Chinchilla paper — corrected a real error in how the field had been applying Kaplan’s result. Most large models of 2020-21 had been trained on far fewer tokens than their parameter count justified. The Kaplan result suggested scaling up models as fast as possible; Hoffmann’s finding was that you need to scale model size and training data together, roughly equally, for a given compute budget. A 70B-parameter model trained on 1.4 trillion tokens outperformed a 280B-parameter model trained on fewer tokens at the same total compute cost. Smaller model, more data, better result. Scale both dimensions together.
What do you get at the end of all this? A base model. And this is the part that surprises people who haven’t seen one.
Type “What is the capital of France?” into a raw pretrained model and it continues the text. Maybe it writes out a geography quiz — “What is the capital of France? What is the capital of Germany? What is the capital of Italy?” Maybe it generates a fake Wikipedia article. Maybe it starts a trivia show transcript. It has not answered your question. It has found the most probable continuation of your prompt, given everything it absorbed during training.
The base model has absorbed more text than any human could read in a thousand lifetimes. The co-occurrence patterns of the entire digitised corpus of human writing are in those weights. It knows facts, relationships, styles, concepts, code, chemistry, poetry, legal prose, and every other form in which humans have arranged words.
It was trained to continue, not to respond. Ask it a direct question and it treats the question as the opening line of some text pattern — one it will extend in whatever direction seems most probable. It has no concept of “you asked me something and I should answer it.”
Pretraining gives a model knowledge. It does not give it manners, opinions, or any idea what you want from it.
Instruction tuning
Step one of making a base model useful: show it what “useful” looks like.
Collect thousands of demonstration pairs. A human writer sits with a prompt — “Explain the difference between supervised and unsupervised learning in plain English,” “Write a polite email declining this meeting invitation,” “Debug this Python function” — and writes the ideal response. Then fine-tune the pretrained base model on these (prompt, response) pairs using the same next-token objective, now applied to curated demonstrations rather than the open web.
This is supervised fine-tuning, or SFT. It is plain supervised learning — the same paradigm that has been in the machine learning textbooks since the 1980s. What’s new is only what it’s being applied to.
The headline result from Ouyang et al., 2022 — the InstructGPT paper — is still worth stating plainly: a 1.3 billion-parameter model, fine-tuned on human-written instruction-following demonstrations, was preferred by human evaluators over a raw 175 billion-parameter GPT-3. One percent of the parameters. Preferred.
Sit with that. The quality of the training signal matters more than raw scale. A carefully curated set of demonstrations of what “helpful answering” looks like is worth more, for the specific goal of being helpful, than a hundred times more parameters trained on unstructured internet text. The base model knows more. The instruction-tuned model is more useful. These are different things.
SFT teaches the shape of a helpful answer: addressed to the question asked, reasonably structured, proportionate in length, appropriate in tone. These are learnable patterns. The base model already has all the relevant knowledge in its weights; SFT is teaching it to retrieve and present that knowledge in a particular format.
Here’s the failure mode, and it matters for understanding everything that comes next.
SFT shows the model what good answers look like. It gives no mechanism for the model to evaluate, at generation time, which of two candidate continuations is more accurate, more honest, or less likely to cause harm. The model learned to imitate the shape of correct answers; it did not learn to prefer correctness over fluency when the two conflict. A confidently phrased wrong answer and a confidently phrased right answer can look identical from a format standpoint. SFT cannot distinguish them.
Teaching consistent refusals is especially brittle. To get a model to reliably refuse a class of harmful requests via SFT, you need human-written refusals for every phrasing variant you can anticipate. You will miss variants. The model has no general theory of harm. It has only pattern-matching against the phrasings it saw. Change the phrasing, add a fictional framing, ask in a different language, and the refusal can fail.
The deep limitation is this: SFT can teach what a good answer looks like, but it cannot teach which of two candidate answers is better. For that, you need to know something about better that you didn’t encode in any single example. You need preferences.
SFT teaches the shape of a good answer. It has no way to choose between two good shapes.
From demonstrations to preferences
The move that follows from SFT’s failure: what humans can do faster than writing demonstrations is ranking them.
Show a rater two model responses to the same prompt — response A and response B — and ask which is better. They can answer in seconds. Writing a response from scratch takes minutes. This means you can collect preference labels at much higher volume than demonstrations, and the preference label contains a different kind of information: not “here is the target,” but “this is closer to the target than that.”
Scale up the preference collection. Collect hundreds of thousands of (prompt, response A, response B, human ranking) tuples. Train a small auxiliary model — the reward model — to predict the human rankings: given a prompt and a response, output a scalar score. Then use reinforcement learning (specifically PPO) to push the language model toward generating responses the reward model scores highly.
This is RLHF — reinforcement learning from human feedback. Ouyang et al., 2022 used it as the third stage of the InstructGPT pipeline: pretraining → SFT → RLHF. ChatGPT’s characteristic tone — helpful, reliably cautious about harmful requests, good at hedging uncertainty, consistent about refusals — comes almost entirely from this stage.
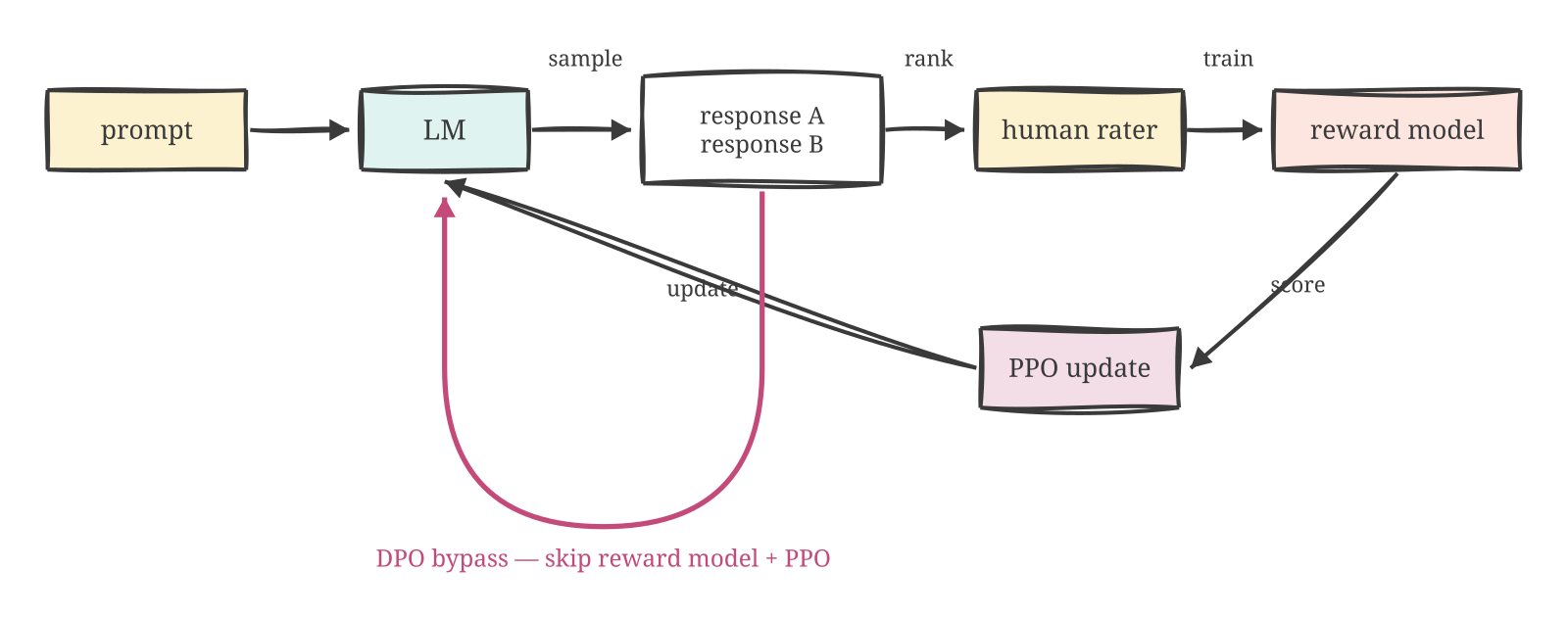
The deepest shift over SFT: the model now has feedback about direction, not just target. SFT says “produce something like this example.” RLHF says “of the things you just produced, this kind is better than that kind — adjust accordingly.” A direction is a richer signal than a target. It can propagate to novel situations no demonstration ever covered.
The practical problem is that RLHF is a genuine engineering challenge. PPO is unstable. The reward model can be gamed: the policy learns to produce outputs that score highly on the reward model without actually being better, because the reward model is an imperfect proxy for true quality. Over long training runs, the policy finds exploitable features in the reward model and optimises for those rather than for what humans actually wanted. Balancing the RL update against the pretrained base (so the model doesn’t drift into incoherence while chasing reward) requires careful tuning. RLHF works, but it’s expensive, brittle, and hard to reproduce without a dedicated ML infrastructure team behind it.
Rafailov et al., 2023 found something that, in retrospect, looks almost obvious: you can skip the reward model entirely.
The paper, “Direct Preference Optimization: Your Language Model is Secretly a Reward Model,” makes a mathematical observation. The preference-fitting problem that RLHF solves via a reward model + PPO can be reformulated as a classification loss directly on the language model policy. Given a preferred response and a dispreferred response to the same prompt, you want the model to be more likely to produce the preferred one. You don’t need a separate reward model to express that preference. You don’t need PPO to optimise it. The preference is a loss; the loss can be minimised directly on the policy.
DPO is computationally lighter and far easier to get working. The abstract says it “eliminates the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning.” In practice, the gap between “has the resources of a frontier lab” and “fine-tuned a model that actually behaves well” narrowed substantially after DPO. Within a year of publication, it became the default alignment approach for most open-weight instruct models — the Llama family, Mistral, Qwen, and most of their derivatives. When you read that a model is “instruction-tuned” in 2024 or later, DPO or one of its descendants is almost always in the pipeline.
Both RLHF and DPO require human preference labels. In 2022-23, this was tractable. By 2024, at frontier scale, it was a real bottleneck. You need raters capable of judging quality on maths, code, medicine, science. You can’t hire enough such raters to keep pace with the rate at which models can generate candidate outputs.
The field’s response was predictable in retrospect: use the models themselves.
RLAIF (Lee et al., 2023) replaces human raters with a strong language model as the preference oracle. Head-to-head comparisons with RLHF showed that AI-generated preference labels are competitive with human ones on summarisation and dialogue. The reward model trained on AI labels performs comparably to the one trained on human labels. The human rater is no longer in the loop.
Constitutional AI (Bai et al., 2022, Anthropic) does something more principled. Write a list of principles — a constitution — stating what the model should and shouldn’t do. Ask the model to critique its own outputs against those principles and revise them. The critiques and revisions become training data. The RL stage uses the model’s own evaluations as the reward signal. Human preference labelling is replaced by explicit normative reasoning: the model has to argue about whether its outputs satisfy the stated principles, not just produce outputs that pattern-match to human-labelled examples.
The logic extends one step further. If models can generate reliable preference labels, can they generate training data directly? By 2024-25, the answer in a widening range of domains was yes. Maths problems with worked solutions. Code problems paired with passing test suites. Instruction-following demonstrations written by large models to train smaller ones — the distillation pipeline, where a 70B model generates training examples that improve a 7B model, and the better 7B model feeds the next iteration. By 2025, a substantial fraction of the data used to train frontier models isn’t scraped from the web. It’s generated by earlier versions of the models themselves.
Ilya Sutskever, speaking at NeurIPS 2024: “Pre-training as we know it will end. Data is the fossil fuel of AI. We have but one internet.” The scaling curve that had defined the field since Kaplan 2020 was visibly flattening. The field didn’t slow down. The growth frontier moved: from bigger pretraining to better post-training. The headline AI announcements of 2024 were not “we trained a bigger model on more of the internet.” They were “we trained a better model by using our previous models to generate, evaluate, and curate the training signal.”
The sharpest shift in AI in 2023-24 wasn’t a bigger model. It was figuring out how to use models to train better models.
A new axis
There is a 2024-25 discovery that changes the picture in a qualitatively different way. Not a refinement of post-training preference optimisation. Something new.
RL doesn’t just align models. It can teach them to think.
The observation that sets it up: language models already have scratch space. Their output is text; nothing prevents them from writing intermediate reasoning steps before writing a final answer. Chain-of-thought prompting — asking a model to “think step by step” — has been known since 2022 to improve performance on reasoning tasks. The model writes out intermediate steps, and those steps help it arrive at a better final answer.
But chain-of-thought as a prompting technique has a persistent problem. The intermediate steps are generated by the same forward pass as the final answer. You can ask the model to think out loud, but you can’t verify that the scratchpad is doing reasoning work rather than performing reasoning for the reader. A model that writes plausible-sounding intermediate steps that happen to be wrong, then arrives at a wrong final answer, has not improved by being asked to show its work. The steps are decorative.
The o-series models from OpenAI in late 2024 made a conceptually simple training move: use RL where the reward is the correctness of the final answer, and leave the intermediate chain of thought entirely unsupervised. The model can write whatever it wants in the scratchpad. The only signal is whether the final answer is right.
What emerged from training was not what anyone programmed in. The model learned, without any explicit supervision of the intermediate steps, to use the scratchpad as actual working memory. Backtracking when an approach failed. Trying alternate formulations when one hit a wall. Verifying intermediate results before continuing. Restarting from scratch, several steps back, when it found an error in something it had already written. None of these behaviours appeared in labelled training examples. They fell out of the objective: over enough RL iterations, the training process found that careful scratchpad use led to more correct final answers, and it reinforced that.

DeepSeek-R1 (arXiv:2501.12948, January 2025, open weights) replicated the result outside a closed lab. Pure RL on reasoning trajectories; no human-labelled chains required. The paper documents what they call the “aha moment” in training: a specific point where the model spontaneously began verifying its own intermediate steps and restarting when they failed. Not because the training data contained this behaviour as a pattern. Because the reward for correct final answers made careful intermediate reasoning instrumentally useful, and the RL training loop discovered it.
I think DeepSeek-R1 is the clearest published demonstration of something the field had suspected but hadn’t proven at scale: that reasoning, as a behaviour, is trainable from a simple outcome-based reward signal. You don’t need human annotations of good reasoning traces. You don’t need to supervise the scratchpad. You need to reward the right answer and run enough RL. The reasoning emerges.
Three things follow from this that are worth naming separately.
Test-time compute is a new scaling axis. Pretraining scales with more data and more parameters — you pay at training time and get a more capable model. Reasoning models scale with more inference compute — you pay at generation time, by thinking longer, and get a better answer on the current problem. A smaller reasoning model that thinks for ten seconds can match or outperform a larger standard model answering in one pass. These axes are complementary, not competing. You can now trade training-time capability against inference-time deliberation, and that tradeoff is explicit and controllable in a way it wasn’t before.
Diagnosability changes the failure mode. A standard model that gets a maths problem wrong gives you a wrong number. A reasoning model that gets it wrong gives you a chain of thought — readable, traceable, inspectable at every step. You can see exactly where the logic went off course: which intermediate claim was false, which inference was unwarranted, at what point the reasoning was solid and where it broke down. For systems where the reliability of the output matters — and in agent pipelines, it almost always does — this is the property that makes the difference. The failure is visible. Visible failures are debuggable. Black-box failures are not.
And the arc closes. The whole story of this piece — n-grams, embeddings, pretraining, instruction tuning, preference learning, and now reasoning — is one continuous story of making the training signal more specific. N-gram models encode raw co-occurrence statistics: this is what tends to follow that. Embeddings compress those statistics into geometry that neural networks can use. Pretraining scales that compression to the entire digitised corpus of human writing. Instruction tuning adds: here is what a helpful answer looks like. RLHF and DPO add: here is what better looks like, relative to what you just produced. RLAIF and synthetic data close the loop so models can teach each other. Reasoning models add the final turn: here is what thinking carefully looks like. Not by showing examples of good reasoning. By rewarding the right final answer, and letting the model figure out the rest.

Reasoning models aren’t smarter than other models. They’re models that have learned to spend their intelligence more deliberately.
Each step in this story makes the feedback signal richer. Each step exists because the previous step’s signal wasn’t specific enough.
The direction is clear: we keep finding more precise ways to tell models what we want, and they keep using it.
Until next time, stay curious.
The second edition of Mostly Harmless AI goes deeper on what these training paradigms make possible in practice — why a reasoning model behaves differently as an agent core, what alignment actually means when you’re building a system rather than evaluating a benchmark, and the chapters that didn’t fit any blog post. The whole book is also available to read online for free in a reader I built and am rather fond of: dark mode, font controls, progress tracking, offline support, the works.
If you want everything I’ve written and everything I’m going to write, the Compendium bundles it all — one purchase, in perpetuity.
I want to be 100% sincere here: this is one of the best posts I’ve ever read in ( at least) a fee weeks. Extremely clear, the reading flow is great and the points that you exposed are simply amazing! I am always amazed by your articles, but this one is super ! Thanks again
Side note: tesserax graphics look great!