


This post is a preview of the first chapter of my WIP book on graphs, The Hitchhikers Guide to Graphs, written in collaboration with Tivadar Danka from The Palindrome.
The full content of the book will be published for free online, but if you want to support its development, please consider getting an early access pass —50% off for the remaining of April—, which gives you access to frequent updates, digital copies of all future versions forever, and a special link to get the print version at cost when it’s published.

Ariadne Wanderlust has been tasked by Major von Veertex with mapping out the legendary underground labyrinth of Graphtopia, where a fearsome beast called the Lurker lives. Many brave adventurers had entered the maze, hoping to slay the monster or find the hidden treasure, but none had ever returned.
Ariadne was not afraid, for she was well-versed in the arcane knowledge of graph traversal algorithms! Before being appointed Chief Explorer, she taught graph search at Graphtopia University and was considered a world expert on depth-first exploration.
She knew what she had to do: walk deep into the maze for as long as possible until she hit a wall, and then backtrack her steps to find an alternative route, carefully marking the walls of the already explored paths to avoid getting stuck in a loop—all adventurers travel with a bag full of chalk, you know?
She hoped to find the Lurker’s lair and then exit before her bag of chalk ran out. However, she soon realized that the labyrinth was more complex and dangerous than she had imagined. It was full of traps, dead ends, and loops. She also heard the Lurker’s roars getting closer as it followed her scent.
She wondered if she had made a mistake by choosing this exploration technique, but it was too late to switch. Now, all she could do was hope to find the exit before the Minotaur could find her.
Modelling the labyrinth
The first step in solving any problem with graphs is to turn that problem into a graph problem!
In this case, we must find a way out of the labyrinth, so we must decide how to model it as a graph such that nodes and edges map to concepts in the labyrinth that are useful for this task. The most natural mapping, and the one you’re probably thinking about, is using edges to model the corridors in the labyrinth and nodes to model the intersections.
Here is a possible depiction of a labyrinth as a graph:

In this model, the solution to our problem –finding a way out of the labyrinth– translates into finding a sequence of nodes, each adjacent to the next, that takes us from the start S to the end E.
Let’s begin by formalizing this notion of “walking” through the graph and meet the most important algorithms that will free Ariadne from the Lurker.
Walking through a graph
The most important structure in a graph is a sequence of connected vertices. In the general case, this is called a walk, where the only restriction is that between any pair of consecutive vertices there is an edge. Let’s look at an example graph to see what we're talking about.
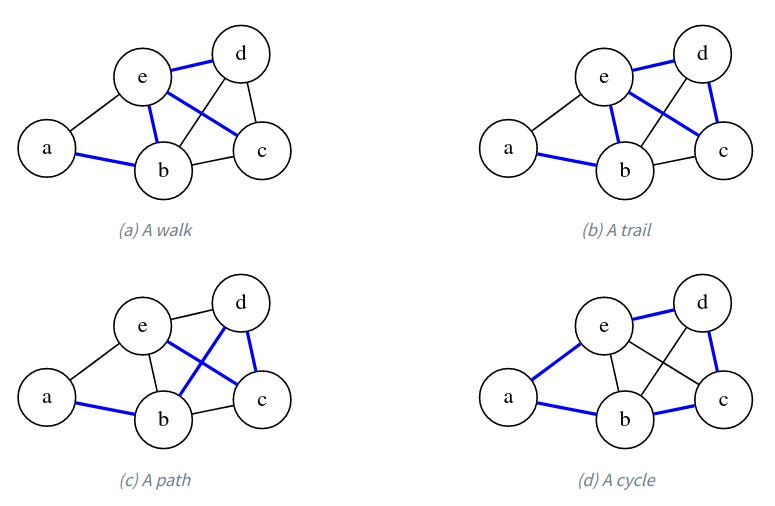
For example, the sequence a, b, e, d, e, c is a valid walk in our example graph, one that happens to touch all vertices. (But a walk doesn’t have to touch all vertices.) Notice that we can move over the same edge back and forth as we want, so we can extend any walk infinitely.
If we never repeat an edge (via backtracking or making a loop), then we have a trail. The previous walk is not a trail because we backtrack through (d,e). But a, b, e, d, c, e is a valid trail in our example graph because although e appears twice, we get to it via different edges each time.
If we also never repeat a vertex, then we have a path. (Some literature will use path to refer to what we call a trail, and simple path to refer to a path with no repeated vertices). In our example graph, a, b, d, c, e is a path that happens to involve all vertices.
If the path loops over from the final vertex back into the first one, like a, b, d, c, e, a, then we call it a cycle.
Graph traversal
The simplest graph procedure involving some notion of “walking” is graph traversal. This task involves enumerating all nodes in a predefined order by moving through the edges. That is, we don’t want to simply list all nodes; we want to order them in a way that uses the graph structure so that subsequent nodes are connected.
There are two basic graph traversal algorithms: depth−first search (DFS) and breadth−first search (BFS). Both algorithms are very similar and will produce a full enumeration of a graph. DFS and BFS differ in how they prioritize being eager versus being comprehensive.
Abstract traversal
We will begin by defining what our abstract notion of “search” looks like. To keep things simple, we assume that a search algorithm provides a single method traverse that simply enumerates all edges in the order in which they are discovered.
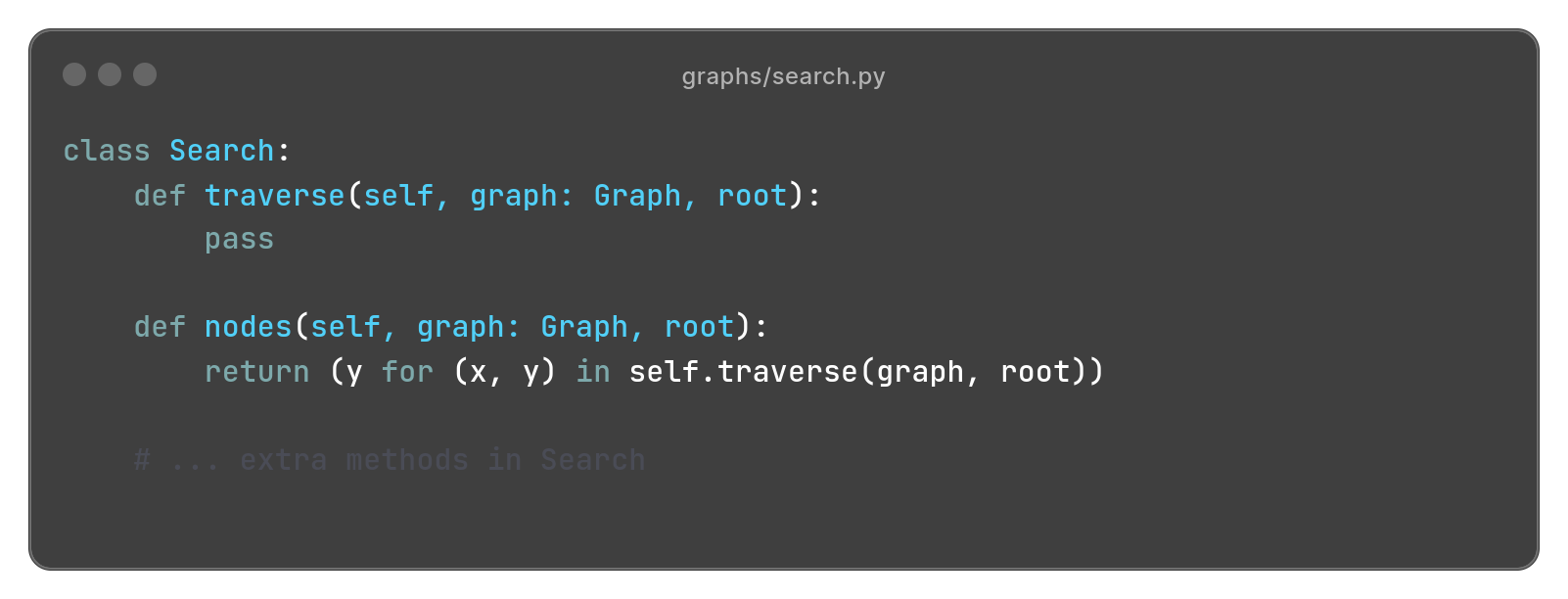
The nodes method is just a thing wrapper around traverse that yields the nodes instead of the full edges.
Why make this a class? Isn’t this just a method? Well, it’s a bit of a mouthful at the moment, for sure. But later, as we explore many search algorithms, we’ll want to compare different strategies. That’s when the search interface will shine.
Plus, this abstract method allows us to implement a very common search pattern that we’ll’ reuse over and over: searching for a specific set of nodes. (Including a single node.) We can have the general−purpose case that matches any node with a given property and the special case when we need to find one particular node −− e.g., like the exit of the labyrinth.

With this code in place, we’re ready for some actual search algorithms.
Depth−first search
As the name implies, depth−first search is a graph traversal algorithm that prioritizes going as deep as possible as fast as possible. In our labyrinth analogy, this means turning right until a dead end and backtracking to the last unexplored intersection.
More precisely, DFS starts at an arbitrary root node in the graph and then jumps to one of its neighbors, continuing the traversal from there. You can select which neighbor to visit by a random choice, but most commonly, one simply defines an order—e.g., the order in which neighbors are listed in the adjacency list.
In a practical scenario, this could mean always trying to move south, east, north, and west. Of course, you must track which nodes (or intersections, in this case) you have already visited. Otherwise, you can easily get stuck in a loop.
This is what DFS looks like in our sample graph that models the labyrinth problem.

Programming DFS
Let’s implement DFS! The easiest way is via recursion1: we start at the root node and recursively visit all non−visited neighbors. To make sure we don’t get stuck in a loop, we keep track of the explored nodes throughout all the recursive calls.
Each iteration returns the edge (x, y), where y is the current node under consideration, and x is the “parent” node −− that we must also keep track of during recursion.
Here is the full implementation:
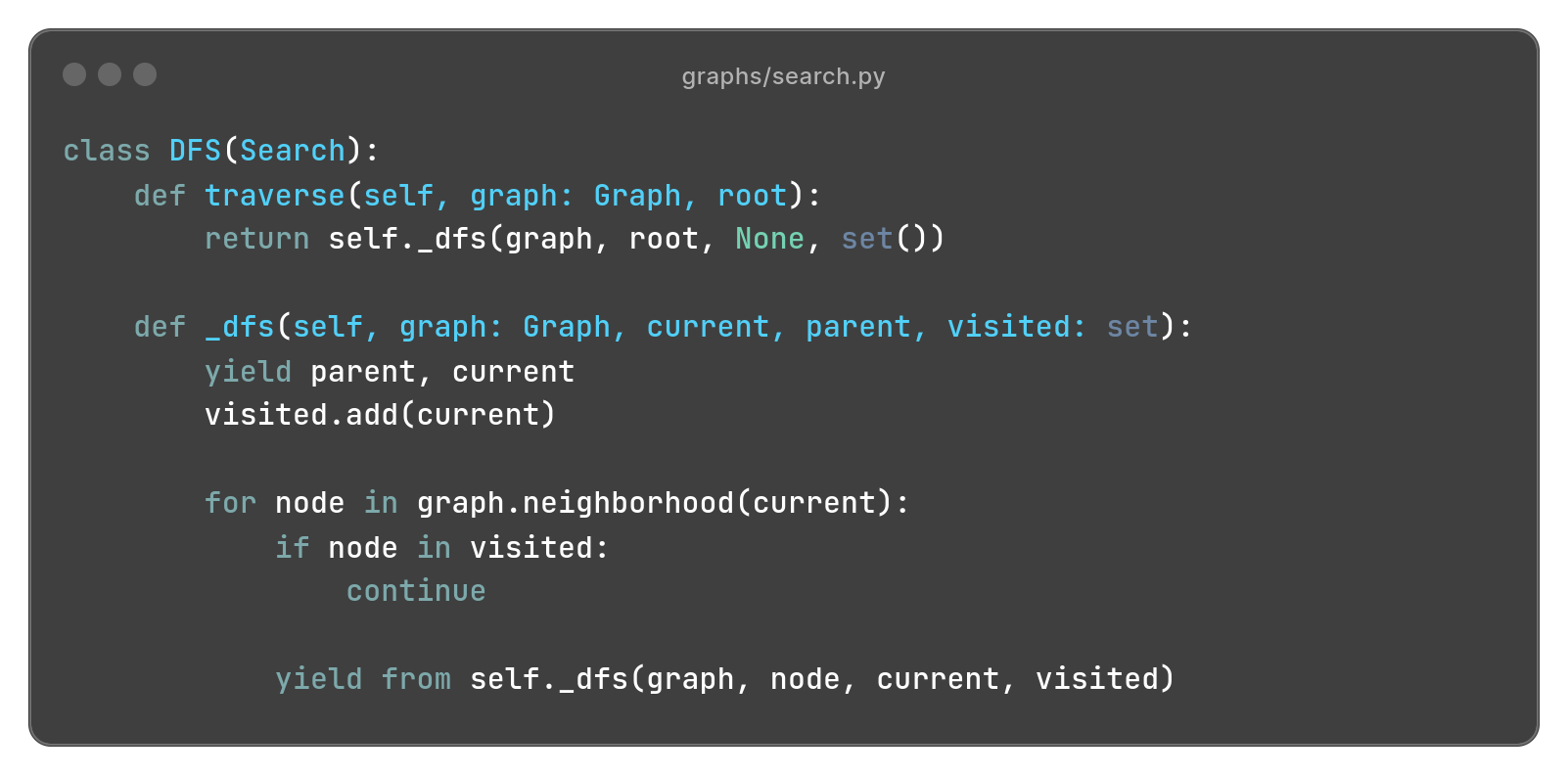
As it’s common in recursive methods, we have a public “portal” method traverse that exposes the public arguments, which in turn defers to a private implementation _dfs that takes any additional arguments we need for bookkeeping.
Finding your way out
Armed with the arcane knowledge of depth−first search, it is now trivial to exit the labyrinth (provided there is indeed a way out). We just need to run DFS in the start node and, eventually, we will reach the end node. We might have to backtrack once or twice if we are unlucky to pick to wrong turn, but as long as we keep track of every node we visit, and make sure not repeat any of them, the way out is guaranteed to be found.
Computing paths
While knowing that a goal node exists is useful, we often want to find the actual path that takes us there. Fortunately, our abstract Search strategy can implement this operation easily using the parent from the tuple (parent, node) available in each iteration in the traverse method.
To quickly compute paths, we can define a simple structure (Paths) that stores a reference to the parent of each node found during search. With this information, the path between our origin vertex and an arbitrary destination is easy to compute by following the links backwards. That is, we start at the destination node, and iteratively add the parent node to a list, until we find the origin node. Then, we simply reverse the list.

Paths are origin−dependent (!)
You’ll notice we don’t require an
originparameter in thePaths.pathmethod. That is because this structure holds paths precomputed from a fixed origin node, that is, the node from which the search algorithm started.If you need to precompute paths for arbitrary pairs of nodes, there is little you can do other than using a
Pathinstance for each origin node.
With this structure in place, we can add a method to the Search class to compute all paths for a given graph and origin.

Analyzing DFS
Before finishing, let’s turn our attention now to the analysis of this algorithm. In computer science, we are often interested in answering a few critical questions for every algorithm:
Does the algorithm always work?
How fast does it work?
How much memory does it need?
Is there any better algorithm?
The first question asks about the correctness of the algorithm. An algorithm is only useful if it always works −− or if, at least, we can determine beforehand whether it will work or not. In the case of DFS, we can claim with absolute certainty that, if there is a path from origin to destination, the algorithm will eventually find it.
¿Why? We can give an intuitive justification of correctness for DFS as follows. Since we never repeat any vertex, and we explore all neighbors of the vertices we visit, we must visit every vertex, that is reachable from the origin, eventually.
Now, there is one massive caveat with DFS. You have no guarantee the path you find is ₜhe shortest path_ from the origin to the destination. Because DFS walks down a path as long as possible, and then never revisits those nodes, you can actually discover the destination first by going throught the long way, instead of taking a shortcut.
The second and third questions ask about the performance of the algorithm. If we want to compare two algorithms for the same problem, there are almost always at least two obvious dimensions: running time and memory requirement. We usually want the fastest algorithm, provided we have enough memory to run it, right?
Now, for reasons beyond the scope of this book, it is almost always useless to think in terms of actual time (like seconds) and memory (like megabytes), since the exact values of those properties for any given algorithm will depend on many circumstancial details like the speed of your microprocessor or the programming language you used.
Instead, to compare two algorithms in the most abstract and fair possible way, we use a relative run−time and memory, that just considers the “size” of the problem. In most cases in this book, the “size” of our problem is something we can approximate by the total number of edges and vertices in our graph.
Thus, we can formulate questions 2 and 3 in terms of, given a graph of n vertices and m edges, how many steps of DFS do we need? You can probably suspect the answer by looking at [@fig−labyrinth−solve] and counting the numbers. You will notice the answer is just the number of edges, since DFS explores the whole graph, and never repeats any path. In general, most search algorithms in this book will take a time that is proportional to the total number of vertices and edges in the graph.
Regarding memory, we could assume we also need something proportional to the total size of the graph, since we need to mark every visited node, right? Well, that is true only if there are loops in the graph. But if you know beforehand there are no loops, then once you hit a dead end and backtrack, you can forget that whole branch up until the bifurcation. This means that, on average, you will only need enough memory to remember as many nodes as there are in the longest possible path in the graph.
Finally, we can ask if there is any way to discover the exit faster. The general answer is “no”, unless we know something special about the graph. That is, in a general graph, without any extra knowledge, you have absolutely no idea where the exit (or the destination nodes in general) will be, so at worst you’ll have to explore the whole graph.
However, as we will see a few chapters down the road, in many ocassions you do know something extra about the graph—e.g., when driving around a city, you have some sense of which direction your destination is. In these cases, we can often speed−up the search massively with some clever strategies.
Final remarks
Depth−First Search is a cornerstone of graph search. Almost all algorithms in this book will either include it as an explicit step, or use it as a building block.
Besides being extremely simple and elegant to implement, DFS is also the easiest to adapt to a real−life situation. Unlike most other graph search algorithms, DFS only moves to adjacent nodes. So, if you are an agent exploring a graph−like structure in real−life—just like Ariadne—DFS is what you would most likely use.
The main caveat of DFS, as we already saw, is that you cannot guarantee that the first time you discover a node, you did so via the shortest path to the origin. In fact, it is easy to come up with examples where you actually reach your destination through the longest possible path; it all depends on how lucky you are selecting which neighboor to visit next.
Next time, we will look at an alternative way to explore a graph that guarantees shortests paths, but it requires that you can teleport to any given node. If you’re want to read the chapters as soon as possible, consider getting an early access pass.
As the saying goes, to understand recursion, you first need to understand recursion.
Whilst I 've not ventured so far as the paths and methods, I found your explanation of the underlying DFS principles really informative.
Today I learned about DFS and the fact that, while it is a simple enough concept to understand in general terms, looking at all the coding related to it makes Daniel feel dumb. Daniel cry. Daniel smashy. Daniel see therapist for anger management.