

Make a Customer Service Bot
Build a simple bot that replies to queries with personalized information from a user profile and general knowledge from a FAQ

Welcome to another Coding Lesson!
Building on the success of the last lesson on making a bot to chat with a PDF file, today we’re reusing some of those ideas to build a customer service bot that can reply to user queries using a combination of profile information and a general knowledge base.
This is a toy example to illustrate a widespread use case. Imagine you have a SaaS product with a FAQ guide containing information such as pricing and features per plan, discount offers, a general description of your service, regional availability, etc. Usually, your service users need to read the guide and find answers about their specific situation: which plan they’re using, what country they’re based on, etc.
Instead of making your users parse the entire FAQ, ignore everything irrelevant to them —such as enterprise offers— and find the relevant information that answers their specific question, you can use an AI-powered chatbot.
This chatbot will answer a user query with information from the FAQ but —crucially— inject into its context details from the current user’s profile, so the answers will be tailored to this user.
If you want to check what that looks like in a toy situation, here’s an online demo you can play with, and here’s a short video of a possible interaction.
The whole source code for this lesson is available on Github.
Prerequisites
This lesson is somewhat advanced, so I expect you to be comfortable with basic Python and building simple apps in streamlit, although most of the streamlit code will be self-explanatory.
You must also know how to set up a basic Python project using a virtual environment and install dependencies from requirement files. If you need help with any of these topics, check out The Python Coding Stack • by Stephen Gruppetta and Mostly Python for plenty of beginner-friendly articles.
You don’t need prior knowledge of using LLMs or vector databases or building chat-based apps.
This post will be cut on your email, so read it here online.
Making a Customer Service Bot
This lesson is somewhat advanced, so I won’t explain the code step by step. Instead, I will give you a high-level description of the app's architecture and then zoom into those crucial implementation details.
My purpose, as usual, is that you understand how each functionality is implemented and how they fit together, so when you read the actual code, everything clicks into place. Thus, I won’t go line by line but rather look at the main blocks in the order that makes understanding the app workflow easier.
At a high level, this is a typical streamlit application with a simple layout. It has a sidebar where the user can upload a PDF file, and the main content is a container for chat UI elements.
The workflow is as follows:
Initially, the FAQ guide is indexed question by question and stored in a flat in-memory vector index using faiss.
Then, the user asks a question.
The user query is embedded, and the top-3 most relevant FAQ entries are extracted.
A custom prompt is built with the FAQ entries and the current user metadata.
Using mistralai, a response is obtained from an LLM.
Go back to step 2.
But the devil is in the details, so let’s dive in.
Indexing the FAQ guide
Let’s assume the FAQ guide is a collection of questions and answers covering most users’ needs. We want to select a subset of 3 relevant questions for a given prompt. We can use the magic of vector embeddings for that.
Our example FAQ guide is a simple markdown document where each question starts with `#`. Go ahead and read it. It’s hilarious.
First, we will split the FAQ into chunks of a manageable size —in this case, one chunk per question.

Once loaded and split, we use the faiss vector library to create a simple flat in-memory index. We can add a bit of streamlit magic to render a progress bar as this indexing takes place.
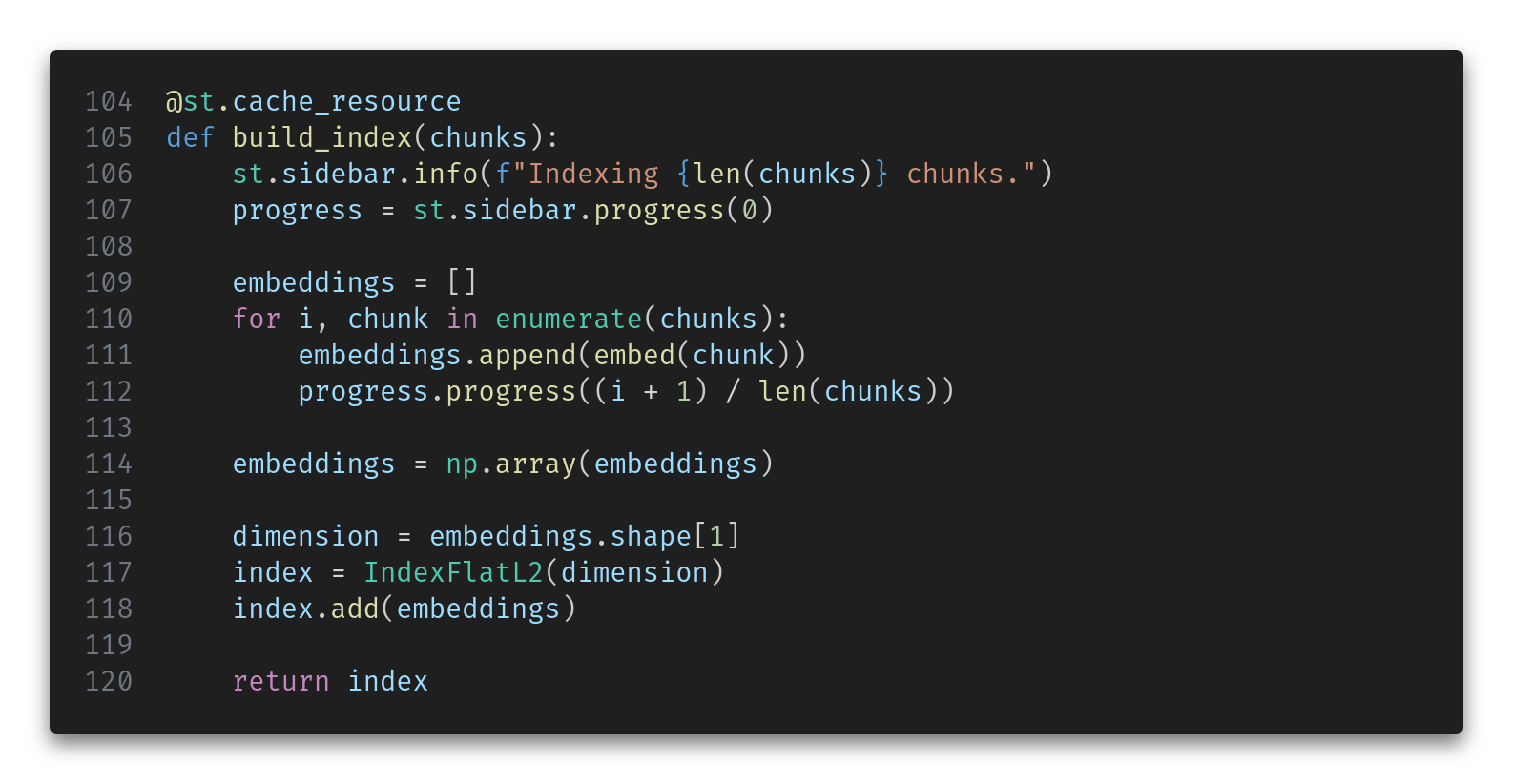
The @st.cache_resource decorator ensures that we only create one index per execution of the application.
The embeddings are computed with a handy function that we will see later.
Answering questions
Once the FAQ guide is indexed, we can take user questions. We will use Mistral AI as our supplier of LLMs because they provide really powerful open-source language models that challenge even ChatGPT.
Here is the monster function to reply to a specific user query.
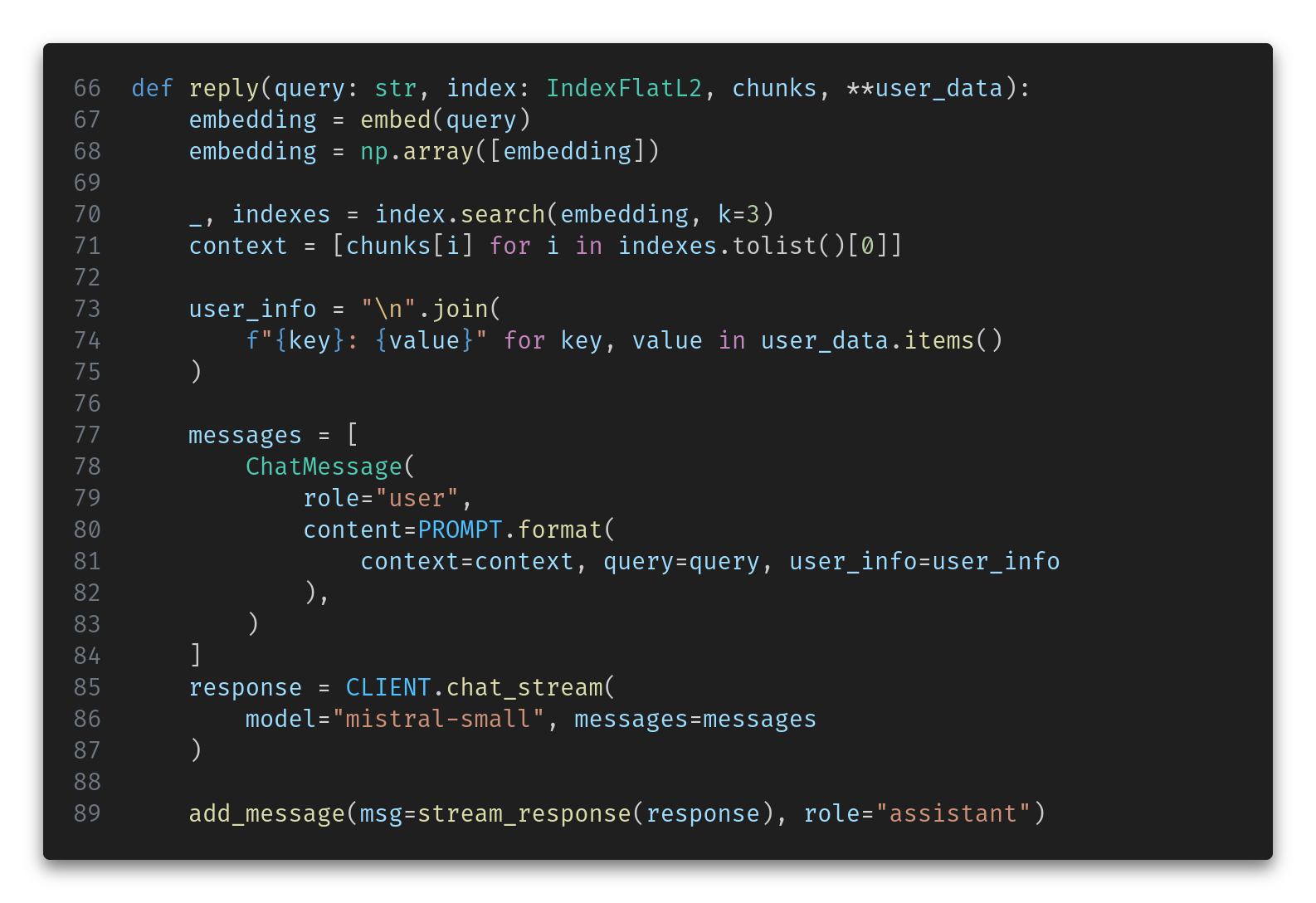
Let’s break it down.
First, we embed the question and query the indexed FAQ to retrieve the top 3 most similar documents. These correspond to 3 questions (and their answers) that are linguistically close to our query, so there is a good chance one of them has the right answer. Here’s the embedding function:

Then, we verbalize the user data (e.g., username, role, credits, plan, etc.) to feed it to the LLM. In this case, we simply produce a line-by-line text in the format key: value, for example:
Username: Neo
Plan: free
Credits: 100
Profession: EngineerFinally, we combine these two pieces of information with the actual query in a custom prompt and send it to the LLM. Here’s the prompt:
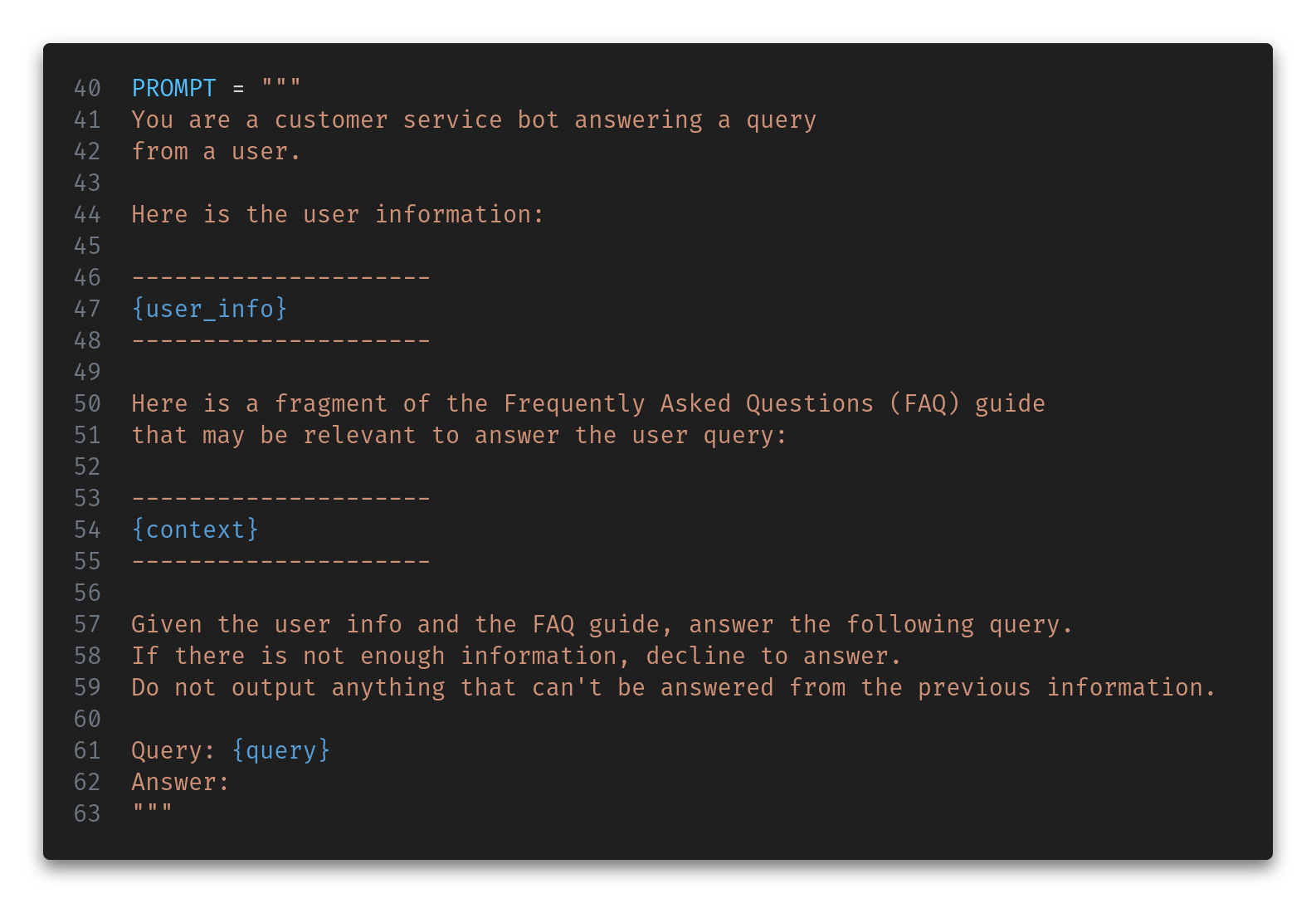
We need a Mistral client correctly configured (assuming you have your API key in the secrets file).

Chat management
The final piece of the puzzle is the actual chat workflow. We will use Streamlit’s chat widgets with some tricks to simulate a conversation.
The gist of the chat management problem is that since Streamlit is stateless, we need to rebuild the entire conversation on each execution. However, we want to show the typing animation only for the last message and simply output the previous history.
We will store all messages in a session state list to achieve this. The add_message function displays the current message (with a nice typing animation) and saves it for later.

The msg argument can be one of two things: a regular string or an actual asynchronous response for Mistral. In the first case, we wrap it in a function that will turn it into a stream of words with some delay in between to simulate it is being typed.
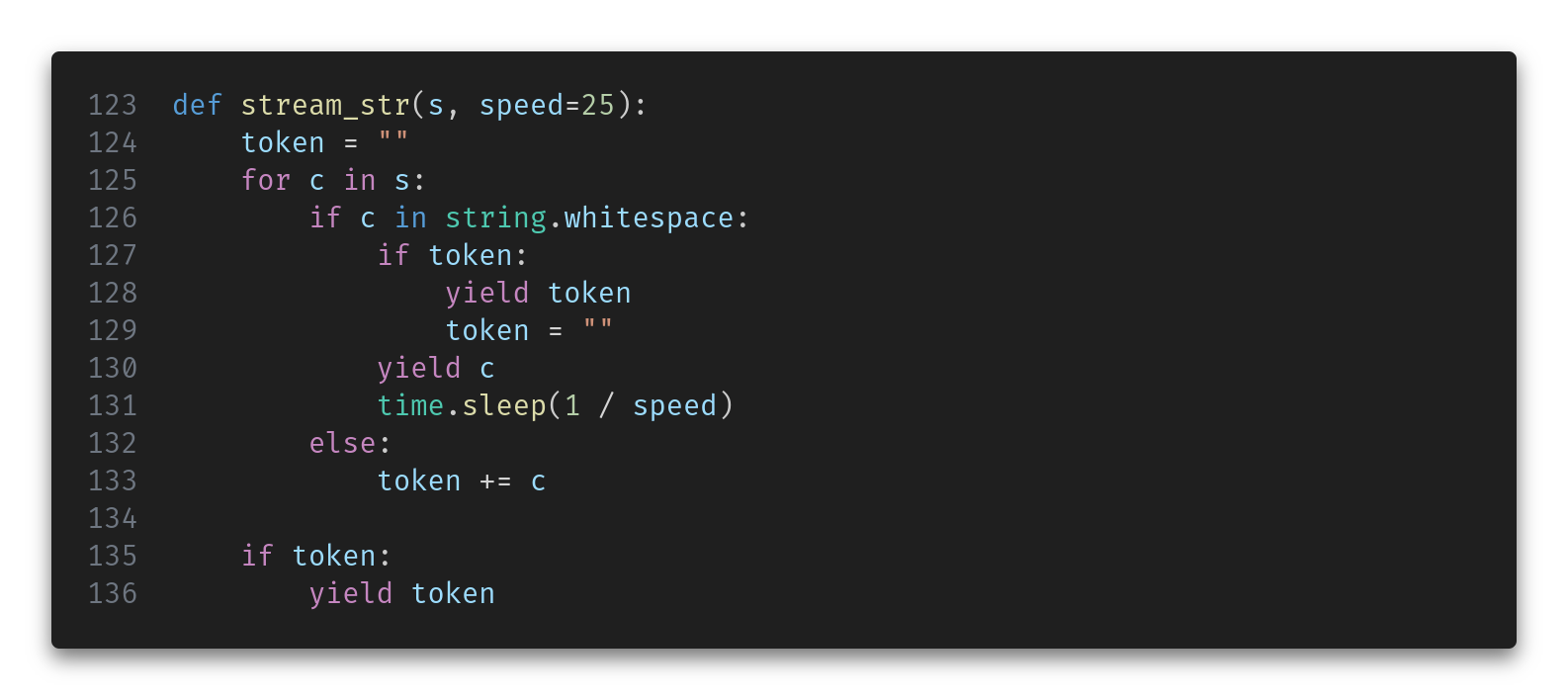
In the second case, we just need to unwrap the generator and yield the actual content:

Putting it all together
Now that all the pieces are in place let’s see how the application workflow works.
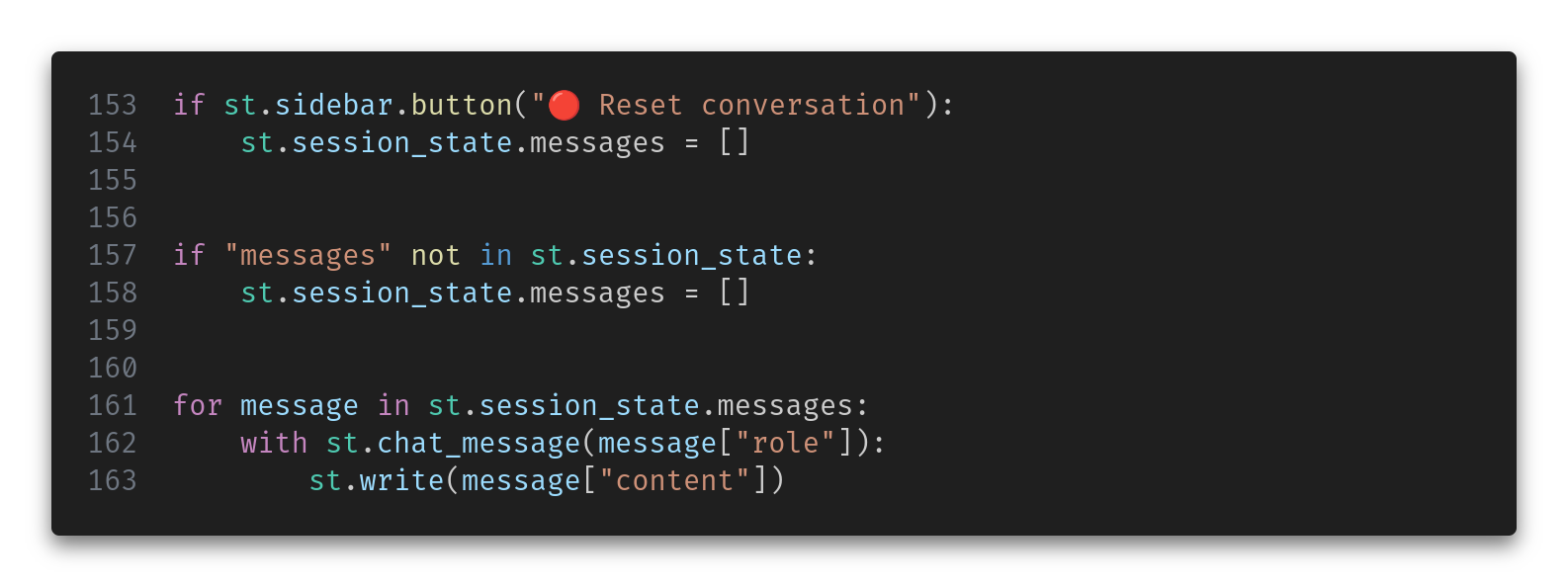
First, we initialize our session state and re-write the chat history:
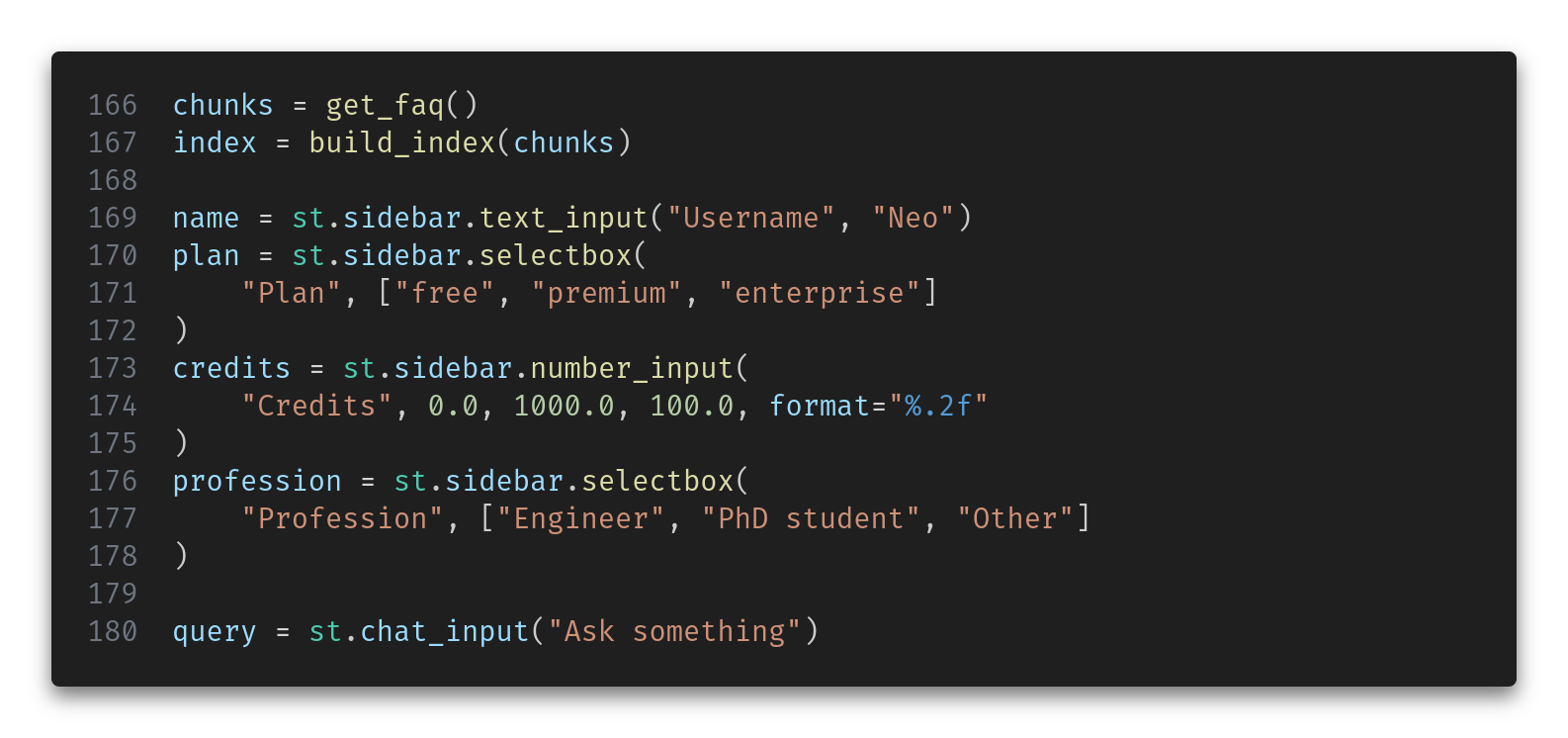
Then, we compute (or simply restore from the cache) the FAQ data and index and get the user data and query.
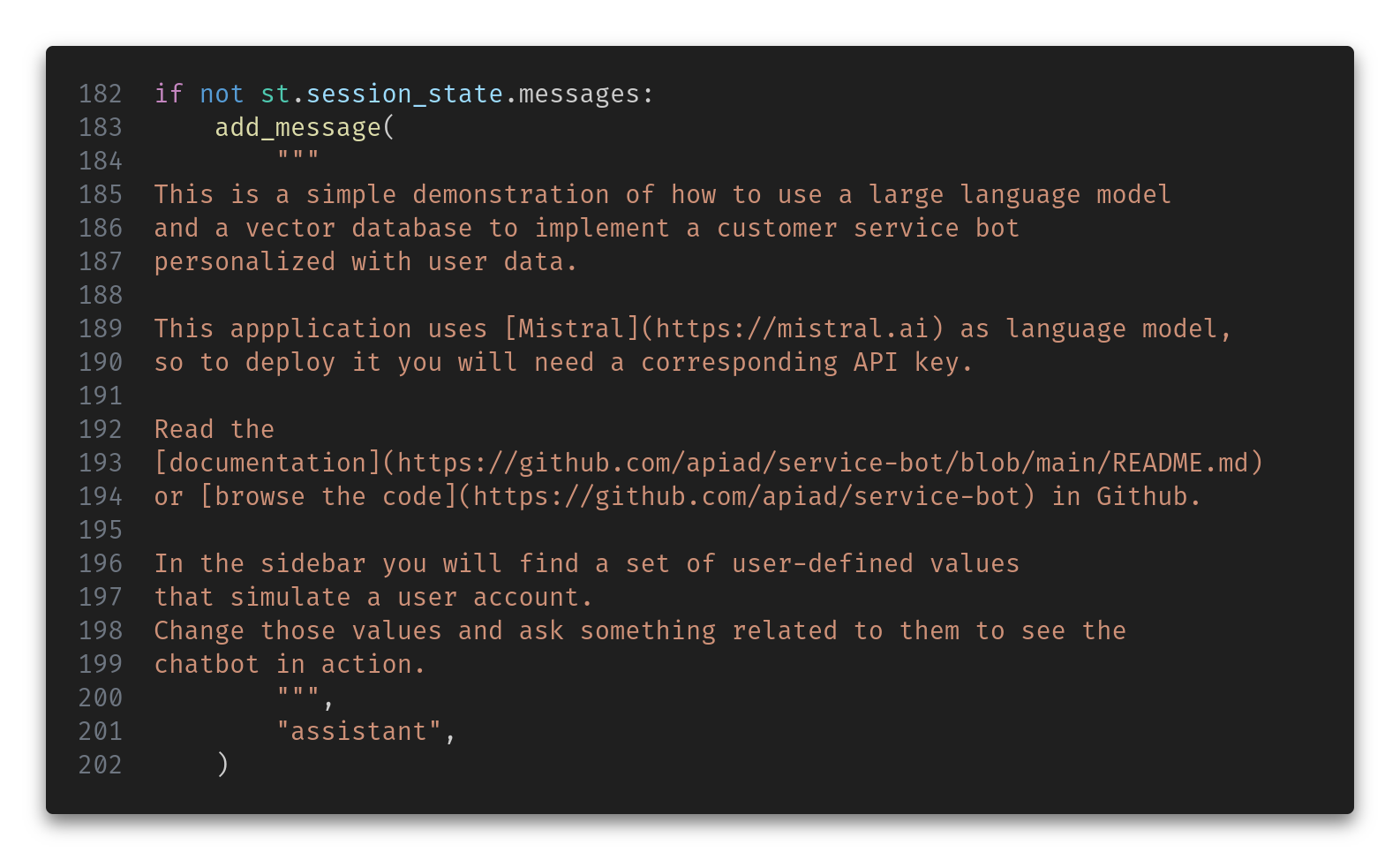
If this is the start of the conversation, we want to output some information.
And since we want the first message from the LLM to be something informative, we query it with this initial request:
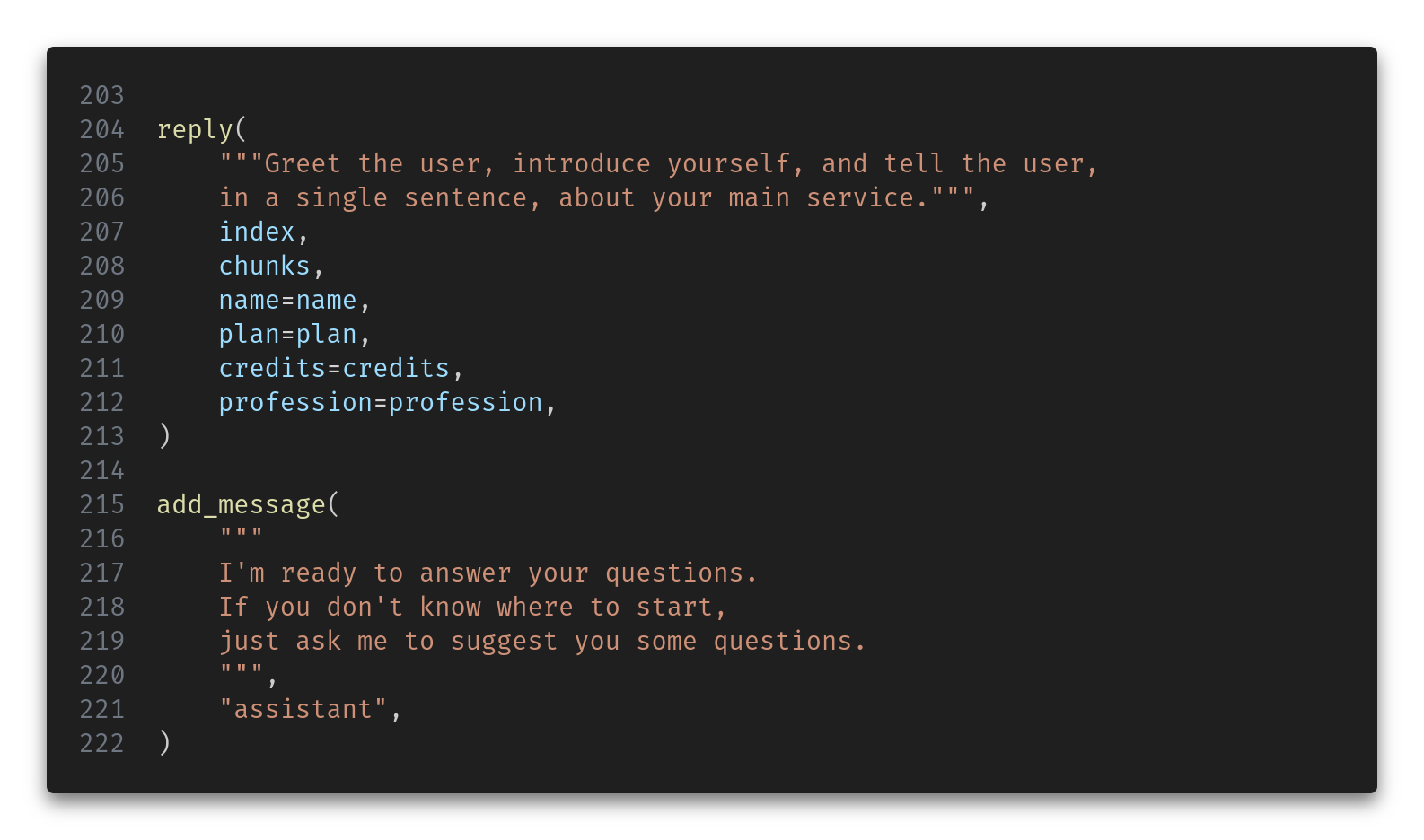
And finally, we take the user query and compute a reply:
And that’s it! In little less than 250 lines of code, you have a chatbot that can answer custom queries combining user data with a general knowledge base.
Moving forward
This simple example can be extended to any length for the FAQ guide (or any other content guide) and any complexity of the user data.
However, if the user data becomes too large, it won’t all fit in a single prompt. You’ll need to apply clever filtering to select the subset of data relevant to the query.
In this case, you can treat the user data as another document, split it into chunks, index it, and let the embeddings do their magic.
Other limitations that might give you ideas for improvement are:
Only the last message is sent to the LLM, so even though the whole conversation is displayed constantly, every query is independent. That is, the chatbot has no access to the previous context. This is easy to fix by passing the last few messages on the call to
client.chat_stream(...).There is no caching of queries, only embeddings. The same query will consume API calls every time it is used. This is relatively easy to fix by caching the query before submission, but you cannot simply use
st.cache_*because the response is a stream of data objects consumed asynchronously, and the same query can have a different response per user/document.Only three chunks are retrieved for each query, so the model will give an incorrect answer if the question requires a longer context.
There is no attempt to sanitize the input or output, so the model can behave erratically and exhibit biased and impolite replies if prompted with such intention.
And that’s all for today. As usual, let me know your opinions about these coding lessons. Are they too specific, too fast, too technical, too dull?
And if you think this is worth it, consider leaving a like and sharing this post with a friend.